How E-commerce Fraud Detection AI Actually Works: The Annotation Layer
TL;DR
- Ecommerce fraud detection AI relies on annotated image data to train models that catch fake listings, counterfeit products, and identity fraud.
- Image annotation types including bounding boxes, polygon segmentation, and attribute tagging each serve distinct fraud detection use cases.
- Manual annotation alone can't scale; hybrid pipelines with model-assisted pre-labeling and human QC are the production-ready approach.
- Label quality directly determines model performance: annotation errors compound at inference and produce costly false positives or missed fraud.
- TaskMonk's managed annotation pipeline handles the volume and QC rigor that ecommerce fraud detection models need to stay accurate over time.
If you've ever had a fraudulent seller slip through your platform's verification checks, you know exactly how it happens: the product images look legitimate, the listing passes automated filters, and the damage is done before a human reviewer catches it. The model flagged something, but the confidence score wasn't high enough to block it. Or it flagged nothing at all.
That gap between 'the model trained on fraud data' and 'the model actually catches fraud' almost always traces back to the training data itself. Specifically, to how those images were annotated before they went into the pipeline. Ecommerce fraud detection AI doesn't learn to spot counterfeits, fake storefronts, or manipulated product photos from raw images. It learns from labeled ones. And the quality of those labels decides how far the model gets.
This article covers how image annotation powers fraud detection in e-commerce, the specific annotation techniques that map to real fraud vectors, and what it takes to build annotation pipelines at the scale these models actually need. Let's get into it.
What Image Annotation Actually Does for a Fraud Model
Image annotation is the process of labeling raw images with structured metadata so that computer vision models can learn to interpret them. That metadata might be a bounding box drawn around an object, a polygon tracing the outline of a product, a classification label assigned to the whole image, or a set of attributes tagged to specific regions. The labels turn unstructured pixel data into ground truth that a model can train on.
For fraud detection, the stakes are higher than for most annotation tasks. When you're labeling product images for a search or recommendation model, a mislabeled item means a slightly worse ranking. When you're labeling fraud training data, a mislabeled fake listing means a model that learns the wrong signal. It starts approving what it should reject.
The types of image annotation used in fraud detection span the full image annotation toolkit: bounding box annotation to localize suspect regions in an image, polygon segmentation to capture precise boundaries of product details, keypoint annotation to map spatial relationships in identity documents, and image-level classification to assign fraud probability labels to entire listings. The choice of annotation type depends on what the model needs to learn.
Pro tip: Don't use bounding boxes when your fraud signal is at the pixel level. If you're training a model to detect manipulated backgrounds or cloned stamps on identity documents, polygon segmentation or even semantic segmentation will produce far better training signal than rectangular boxes that include too much surrounding context.
Leveraging Image Annotation in E-commerce for Fraud Detection
E-commerce platforms generate enormous volumes of image data every day: product listings, seller verification photos, user-uploaded reviews, return requests, and shipping labels. Most of this data sits unannotated and unused for fraud detection purposes, even though it contains some of the clearest signals available.
Product image annotation for fraud typically involves labeling images across several categories simultaneously. A single listing might require object detection labels for the product itself, attribute tags for brand logos and packaging details, quality classification for image authenticity, and region-level flags for signs of digital manipulation. Building a dataset that covers all of these dimensions requires a taxonomy built around actual fraud patterns, not generic product categories.
The practical challenge for ML engineers is that fraud data is inherently imbalanced. Legitimate listings vastly outnumber fraudulent ones. This means annotation teams need to surface and annotate rare fraud examples with high accuracy, since each labeled fraud instance carries more weight in training (sometimes ten times the effective influence of a non-fraud label, depending on your loss function and class weighting). Missing labels or incorrect ones in the fraud class have an outsized effect on model recall. The model misses real fraud because it never learned what it actually looks like.
This is where the annotation strategy for e-commerce fraud diverges from standard product annotation. You need domain-aware annotators who understand what constitutes a suspicious product image, and a QC process that specifically reviews fraud-class labels. TaskMonk's e-commerce annotation services are built around exactly this kind of domain-specific workflow.
The Evolution of Fraud Detection: From Manual to AI-Powered Techniques
Ten years ago, fraud detection in e-commerce was mostly rule-based: flag listings priced suspiciously low, block new seller accounts, review anything that matched a known counterfeit keyword. Simple enough. The problem is that rule thresholds are public knowledge, or they become public knowledge as soon as the first fraudster figures them out and shares it. They learned the thresholds and structured their operations to stay just under them, which is exactly what they did.
Machine learning changed the calculus. Instead of rules that fraudsters could reverse-engineer, models learned patterns from historical fraud data. They could catch anomalies that no human analyst had thought to write a rule for. But this introduced a new dependency: the models were only as good as the labeled data they trained on. A model trained on 2020 fraud patterns will miss the tactics that emerged in 2023. Annotation or AI training data isn't a one-time project; it is an ongoing requirement.
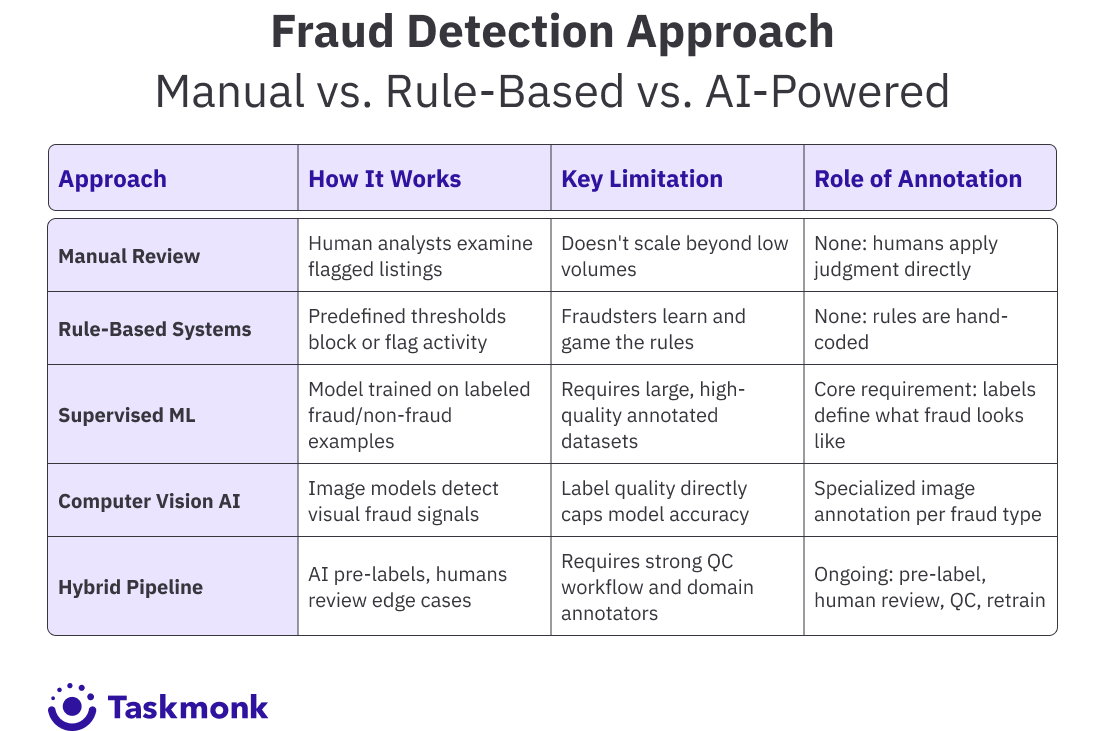
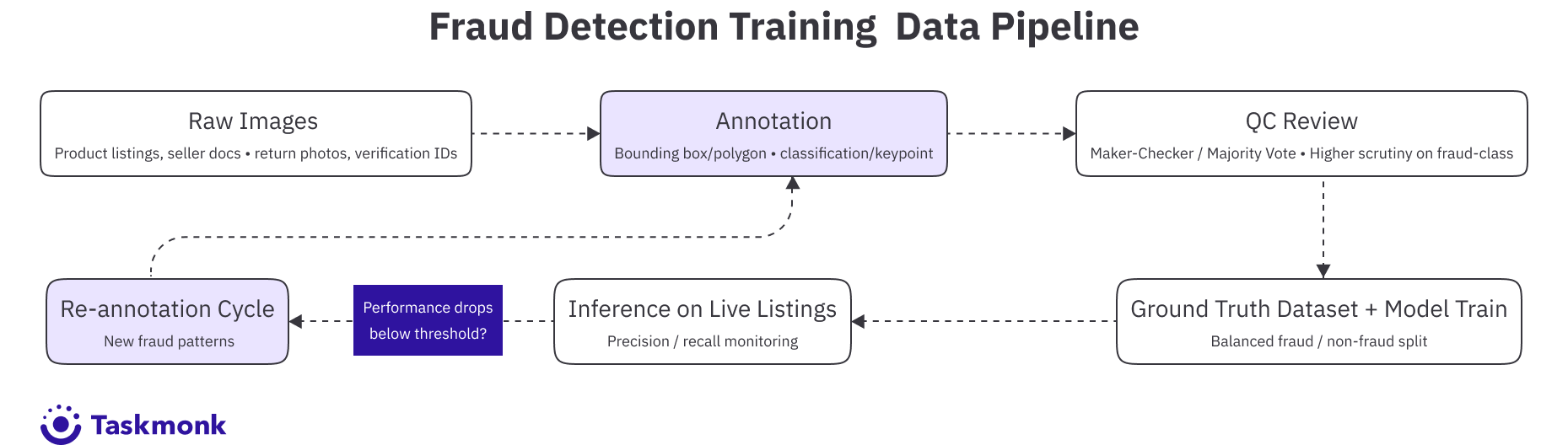
The shift to hybrid pipelines reflects what teams actually learned from building these systems: fully manual annotation doesn't scale, fully automated annotation introduces systematic errors, and the feedback loop between production inference and annotation refresh is what keeps a fraud model from going stale. Data annotation for fraud prevention isn't the first step. It is the continuous thread that runs through the entire model lifecycle.
Pro tip: Build your annotation taxonomy from confirmed fraud cases, not from product categories. If your fraud team has identified 12 distinct visual patterns across your top fraud types, those 12 patterns should map to specific label classes in your annotation spec. A generic taxonomy borrowed from product recognition will miss the fraud-specific signals your model needs to learn.
Detecting Fraud and Enhancing Operational Security
The specific fraud vectors that image annotation addresses in e-commerce break down into a few well-defined categories, each requiring a different annotation approach:
Counterfeit and Fake Product Detection
Training a model to detect counterfeit products requires annotated datasets that include both authentic and fake versions of the same item at a granular level. Annotators label logo placement, stitching patterns, font rendering on packaging, and color consistency. These are all attributes that differ subtly between genuine and counterfeit products. This is polygon-level work, not bounding boxes. The fraud signal is in specific regions of the image, and broad rectangular labels lose the precision the model needs.
Manipulated and Synthetic Image Detection
Fraudsters increasingly use image editing to make low-quality products appear higher-end, or to reuse authentic product photos for listings that ship something entirely different. Annotation for this use case involves classification labels at the image level (manipulated vs. authentic) combined with region-level flags that mark specific areas of suspected editing. Models trained on this data can catch inconsistencies in lighting, shadow direction, background cloning, and metadata mismatches that a human reviewer would spend minutes analyzing per image.
Identity and Document Fraud
Seller onboarding is a major fraud surface. Fake identity documents, altered business registration papers, and reused verification photos all slip through manual reviews under volume. Keypoint annotation maps the spatial structure of identity documents, bounding boxes localize document regions, and classification labels flag whether a submitted document matches expected formatting standards. Models trained on well-annotated document image datasets can process verification queues at a fraction of the time manual teams require.
Return and Chargeback Fraud
Return fraud, where customers claim they received a different or damaged item, often comes with submitted photos as evidence. Annotating these images for visual discrepancies between the listed product and the return photo creates a training dataset for models that can flag suspicious return requests automatically. The annotation spec here needs to cover product condition labels, packaging state, and serial number or label visibility: these details vary significantly by product category and require annotators who know what an authentic return actually looks like, not just what a damaged product looks like.
Pro tip: Seller verification image annotation and product listing annotation need separate taxonomies and separate annotator pools. A person who's good at labeling brand logos on luxury goods probably isn't the right reviewer for spotting manipulated business registration documents. Route tasks to annotators with the right domain background, or your recall on the harder fraud classes will suffer.
Implementing AI Fraud Detection in eCommerce Platforms
Knowing which annotation type to use for each fraud vector is step one. Building the pipeline that produces that annotation at production scale is a different problem entirely. The annotation pipeline needs to be designed around the model's actual training requirements, and that design work happens before the first image gets labeled.
Start with a fraud taxonomy that maps to your confirmed fraud cases. Pull from your fraud team's incident logs and categorize the visual patterns they've identified. Each pattern becomes a label class. This sounds obvious, but most teams skip it and default to a generic annotation schema that doesn't capture the specific signals their models need to learn.
Next, address class imbalance deliberately. Fraud examples in your dataset will always be outnumbered by legitimate ones. Decide on your target ratio during dataset design, and build your annotation workflow around sourcing enough positive fraud examples. This often means running targeted collection campaigns for specific fraud types rather than annotating a random sample of your production data.
QC is where most annotation pipelines for fraud detection underinvest. Because the fraud class is rare, a QC process that samples randomly across all labels will review very few fraud examples. You need a QC layer that specifically reviews fraud-class labels at a higher rate, using a method like Maker-Checker or Majority Vote to catch disagreements on the labels that matter most. A 3% error rate in your non-fraud labels won't hurt model performance much. A 3% error rate in your fraud labels will.
Finally, build the retraining loop before you need it. Fraud patterns change, and a model trained six months ago will start missing tactics that emerged in the last quarter. Build annotation refresh into your pipeline. Not as a one-off project but as a scheduled process tied to your model's performance metrics in production. When precision or recall drops below threshold, that's the trigger to collect new examples and annotate them.
Where Fraud Detection AI Is Heading, and What It Demands from Annotation
The next generation of ecommerce fraud detection AI is moving toward multimodal models that combine image signals with behavioral, transactional, and text data in a single inference pipeline. An image of a product listing gets evaluated alongside the seller's behavioral history, the listing's text description, and the price point, evaluated in one pass. This makes annotation harder, because each data type needs its own labeled dataset, and the signals need to be consistent across modalities.
Synthetic data generation is gaining traction as a way to address class imbalance in fraud datasets. But here's the problem teams hit first: how do you generate synthetic fraud images that match patterns you haven't fully characterized yet? In practice, teams generate images against known fraud patterns and annotate those. Models trained on a mix of synthetic and real fraud examples tend to generalize better to novel fraud types than models trained on historical data alone, because the synthetic examples cover pattern variations that haven't appeared in production yet. But this approach has a ceiling: synthetic data still needs to be validated against real fraud patterns, and that validation is an annotation task.
Federated learning approaches are emerging for platforms that can't centralize fraud image data across regional operations or partner networks for privacy reasons. Models train locally on each node's annotated data and share gradients rather than raw data. This expands the effective training dataset without requiring data consolidation. The annotation requirement does not go away. It distributes. Each node needs its own annotation workflow and QC process.
AI-driven ecommerce fraud management will also increasingly rely on models that can explain their decisions, not just flag a listing but identify which visual features triggered the flag. This interpretability requirement adds a new dimension to annotation: annotators need to label not just whether something is fraudulent but which specific visual attributes contributed to that classification. That's a harder, more expensive annotation task, and it's one most teams aren't prepared for yet.
Supercharge Your E-Commerce Growth with TaskMonk’s Image Annotation Services
The hard part of building a fraud detection pipeline isn't finding an annotation tool. It's building the operational infrastructure around it: the taxonomy, the annotator selection, the QC workflow, the feedback loop. The annotation layer routinely surfaces as one of the top two causes of delayed model deployment in computer vision pipelines, and errors in annotation rarely surface until weeks into training, by which point the rework cost is significant.
That is where a partner like Taskmonk can help, with their vast experience of edge cases & ai failure modes discovered across millions of annotations performed for some of the largest global retailers like Flipkart, Myntra & Walmart. Here are some features that make this work:
Managed annotation pipeline: TaskMonk handles annotation as a managed operation, not just a software layer. That means the workflow configuration, the annotator assignment, and the QC process are all part of what you're getting. You're not setting up pipelines from scratch or managing a freelance annotation team. You are handing off a well-defined annotation spec and getting back a validated dataset.
Domain-matched annotators: Fraud annotation requires annotators who know what they're looking for. TaskMonk's affinity-based routing matches tasks to annotators by domain expertise, so product image fraud labels go to reviewers familiar with the product category, and document fraud annotation goes to annotators with document verification experience. This isn't a nice-to-have. It directly affects recall on the fraud class.
QC methods that protect the fraud class: TaskMonk supports three QC methods & execution levels: Maker-Checker, Maker-Editor, and Majority Vote. For fraud detection datasets, Majority Vote on the fraud class specifically is the approach that catches the disagreements that matter. You can configure different QC methods by label class: higher scrutiny on fraud labels, lighter-touch QC on clearly legitimate ones.
Model-assisted pre-labeling: For large-volume annotation jobs, TaskMonk's pre-labeling capability runs a trained model over the raw images before human annotators see them. Annotators review and correct the pre-labels rather than starting from scratch. On fraud datasets, this accelerates throughput on the non-fraud class and reserves annotator attention for the edge cases where the model's confidence is low, which is usually where the interesting fraud signals live.
TaskMonk has processed 480M+ tasks, logged 6M+ labeling hours, and supported more than 10 Fortune 500 teams across annotation projects, with an unmatched depth in ecommerce globally. The platform holds a 4.6/5 rating on G2 and covers annotation across image, video, document, and multimodal data in a single workflow.
If you're building or refreshing a fraud detection model and need annotation at scale, book a demo with the TaskMonk team. They'll walk through your fraud taxonomy and show you how the annotation and QC workflow would map to your specific pipeline.
Conclusion
The teams that lose to fraud aren't usually losing because they don't have AI models. They are losing because those models are training on annotation that was good enough for product recognition but not rigorous enough for fraud detection. A taxonomy built for catalog management won't teach a model to distinguish a counterfeit from the real thing. A QC process that samples uniformly across label classes will sign off on fraud-class errors that quietly tank model recall.
The teams that get this right treat annotation as a first-class engineering concern, not an outsourced afterthought. They build fraud-specific taxonomies, configure QC workflows around their highest-stakes label classes, and build the retraining loop into the product before the model ships, not after performance degrades in production.
Image annotation is what sits between raw visual data and a fraud detection model that works. Getting that layer right is the job.
Frequently Asked Questions
What types of image annotation are most effective for ecommerce fraud detection?
There's no universal answer here, but the choice almost always comes down to where the fraud signal lives in the image. Bounding box annotation works well for localizing suspect regions in product listings or flagging document fields. Polygon segmentation is better when the fraud signal is at the boundary level: logo authenticity, packaging edge details, or identifying cloned regions in manipulated images. Image-level classification labels are useful for binary fraud/non-fraud sorting at scale. Most production fraud detection pipelines use a combination: classification to triage, then localization annotations for the model to learn from on the positive fraud class.
How much annotated data does a fraud detection model typically need?
There's no universal answer, but fraud detection is particularly data-hungry because of class imbalance. A reasonable starting point for a computer vision fraud model is 5,000 to 10,000 annotated fraud examples per fraud type, with roughly 3 to 5 times as many legitimate examples to match the natural ratio in your production data. If you're working with rare fraud vectors, you may need to use synthetic data augmentation to reach a usable training set size. More important than raw count is label quality. 3,000 carefully annotated, QC-verified fraud images will outperform 15,000 inconsistently labeled ones.
Can automated annotation tools replace human annotators for fraud datasets?
Not for the fraud class. Automated tools perform well on high-volume, low-ambiguity tasks, like pre-labeling clearly legitimate listings, for example. But the fraud examples in your dataset are precisely the cases where automation fails: they're edge cases by definition, and a model that hasn't been trained on them yet can't reliably annotate them. The right approach is hybrid: use model-assisted pre-labeling to handle throughput on the non-fraud class, and route fraud-class images to domain-aware human annotators for final labeling and QC.
How do I keep a fraud detection model accurate as fraud tactics evolve?
Build annotation refresh into your production workflow before the model ships. The trigger should be model performance in production: when precision or recall drops below your threshold, that signals new fraud patterns the model hasn't seen. Collect examples of the newly emerging fraud type, run them through your annotation pipeline, add them to your training set, and retrain. The annotation workflow needs to be fast enough to respond to fraud pattern changes on a timeline of weeks, not quarters. Teams that treat annotation as a one-time project will find their models degrading within months of deployment.
What’s the difference between data annotation for fraud prevention and standard product image annotation?
The main differences are in taxonomy design, annotator requirements, and QC intensity. Standard product annotation uses category and attribute taxonomies built for search and recommendation. Fraud annotation taxonomies need to capture the specific visual signals that distinguish fake from authentic. This requires input from your fraud investigation team, not just your ML engineers. Annotators for fraud tasks need domain familiarity with the product category and fraud patterns, not just general image labeling experience. And QC needs to apply higher scrutiny to the fraud class specifically, since those labels carry more weight in training than the majority non-fraud class.
.png)