TL;DR
- Image annotation for fashion e-commerce trains AI models to recognize clothing attributes, enabling visual search and automated product tagging
- Core techniques include bounding boxes for product detection, semantic segmentation for virtual try-on, and keypoint annotation for garment structure analysis
- Quality annotation reduces manual catalog work by up to 60 percent, cuts return rates through better fit accuracy, and powers personalized recommendations
- Major fashion retailers using annotation-powered AI report 30 to 40 percent improvement in visual search conversion and 25 percent reduction in return rates
- Development requires taxonomies covering 150 plus attributes, annotators trained on fashion terminology, and QC workflows that catch edge cases like occluded garments
A shopper screenshots an outfit from Instagram, uploads it to a fashion retailer's app, and instantly finds similar pieces across the catalog. The dress, shoes, and bag all match the style. She adds three items to cart without typing a single search term. That workflow exists because someone annotated 50,000 product images to teach the AI system what "floral midi dress with ruffled sleeves" actually looks like in pixels.
Fashion e-commerce runs on visuals. Customers browse with their eyes, not just keywords. They want to find a black leather jacket with gold hardware, not scroll through 2,000 generic "jacket" results. Image annotation is how retailers make that precision possible. It trains computer vision models to recognize garment types, colors, patterns, fabrics, fits, and style details so the AI can surface the right product when a customer searches visually or filters by specific attributes.
But annotation in fashion isn't just drawing boxes around dresses. It requires domain knowledge. Annotators need to differentiate a crew neck from a boat neck, flag occluded garments when a model's arm covers the sleeve, and handle edge cases like transparent fabrics or reflective accessories. Get the labels wrong, and the model learns the wrong patterns. The visual search fails. The product recommendations miss the mark. Returns go up.
This article covers what image annotation for e-commerce actually involves, which annotation techniques matter for product catalogs and visual AI, and how annotation quality directly impacts customer experience and revenue. Let's get into it.
What is Fashion Image Annotation?
Fashion image annotation is the process of labeling product images with structured metadata so computer vision models can learn to identify clothing items, accessories, and their attributes. Annotators draw shapes around products, tag visual characteristics like color and fabric, and assign class labels that define what the model's looking at. The output becomes the training data that powers visual search, automated product tagging, recommendation engines, and virtual try-on systems.
The core work involves three layers. First, object detection identifies where each product appears in an image. A bounding box isolates a dress, a pair of shoes, or a handbag from the background. Second, attribute tagging labels visual properties like sleeve length, neckline type, pattern style, or heel height. Third, segmentation creates pixel-level masks that separate the garment from the model wearing it, which is required for virtual try-on applications that overlay clothing onto a shopper's photo.
Fashion annotation differs from general image annotation because the taxonomy is industry-specific. A model trained on generic object detection datasets can recognize "shirt" but not "puff-sleeve blouse with Peter Pan collar." Fashion retailers need annotations that capture style nuances, fit details, and material types, because that specificity is what separates a conversion from a bounce. The annotator viewing a product photo needs to know the difference between a wrap dress and a shift dress, or between espadrilles and mules, and that requires domain training most computer vision annotation teams don't have by default.
Pro tip: Annotation quality in fashion hinges on taxonomy completeness. If your spec doesn't define how to label occluded sleeves, cropped product shots, or garments with mixed patterns, annotators will make inconsistent choices. Build the edge case rules before the first batch, not after the first model fails.
Once annotated, these labeled images train machine learning models through supervised learning. The model sees thousands of examples: this bounding box contains a black leather jacket, this one contains a floral midi dress, this segmentation mask outlines a pair of sunglasses. Over time, the model learns the visual patterns that define each category and attribute. When a new product image arrives, the model predicts the labels based on what it learned from the training data. The accuracy of those predictions depends entirely on the quality and consistency of the annotations that trained it.
Why Fashion E-commerce Needs AI Image Annotation
Fashion retailers process massive visual catalogs. A mid-sized e-commerce platform might carry 50,000 active SKUs. Each product needs accurate metadata for search, filtering, and recommendations. Manual tagging at that scale is slow, expensive, and inconsistent. One merchandiser tags a dress as "midi," another calls it "tea-length." The search bar returns different results depending on who wrote the product copy. Customers searching for "floral print" miss half the inventory because some listings say "flower pattern" instead.
AI-powered annotation solves this by creating structured, consistent labels across the entire catalog. Computer vision models trained on annotated product images can automatically detect garment types, identify colors and patterns, and assign attribute tags without human intervention. The system processes thousands of images per hour with the same taxonomy applied to every product. That consistency improves search accuracy, reduces catalog maintenance costs, and makes product discovery faster for customers who filter by specific attributes like "crew neck" or "A-line skirt."
Visual search is the second driver. Shoppers now expect to upload a photo and find matching products instantly. Pinterest reports 1.5 billion visual searches per month, as of late 2025.. Facebook Marketplace uses AI to generate product metadata from images. Fashion retailers without visual search capabilities lose customers who shop visually first. Image annotation for fashion e-commerce is the foundation of those visual search systems. Models need training data that shows them what a "black ankle boot with block heel" looks like from multiple angles, in different lighting, worn on different body types. The more diverse and accurate the annotated dataset, the better the visual search performs when a customer uploads an actual photo.
Personalization is the third reason annotation matters. Recommendation engines need to understand visual similarity to suggest products a customer might like based on past browsing behavior. If someone clicks on five floral dresses, the system should recommend more floral patterns, not just any dress. That requires the model to recognize "floral" as a visual attribute, which it learns from annotated training data. The same logic applies to fit recommendations. A customer who favors oversized silhouettes should see more relaxed-fit options. The AI can only make that connection if the training data includes fit annotations tied to each product image.
Returns are a fourth pressure point. E-commerce fashion return rates average 20 to 30 percent Many returns stem from fit issues or unmet expectations set by inaccurate product descriptions. Virtual try-on systems powered by segmentation-based annotation reduce returns by showing customers how a garment fits their body type before purchase. If the annotation quality is high, the virtual overlay aligns correctly. If the segmentation masks are sloppy, the garment appears distorted and the feature becomes unusable. [POV — TaskMonk client case] One major fashion retailer reported a 25 percent drop in return rates after deploying AI-powered fit recommendations trained on pixel-accurate annotated images.
Types of Fashion Image Annotation
Fashion e-commerce annotation uses several techniques depending on the AI task. Each method serves a specific purpose in the product discovery and recommendation pipeline. Teams often combine multiple annotation types in the same dataset to train models that handle detection, classification, and segmentation simultaneously.
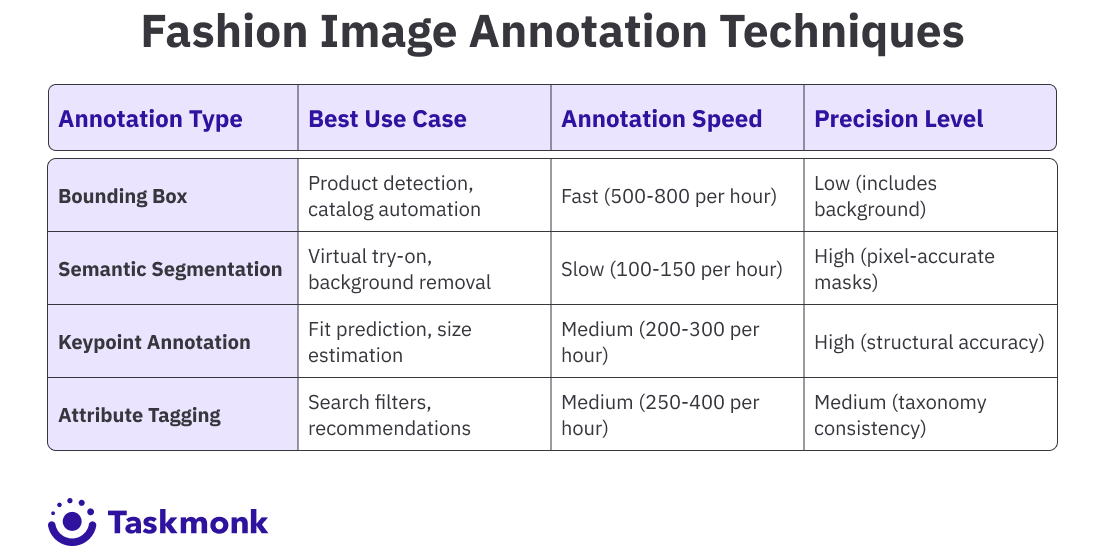
Bounding Box Annotation
Bounding boxes draw rectangular frames around products to isolate them from backgrounds, models, and other objects in the image. This is the fastest annotation method and works well for object detection tasks where the goal is to locate products on a page. A lifestyle photo showing a model wearing a jacket, jeans, and sneakers gets three bounding boxes: one per item. The model learns to detect each product type and predict its location in new images.
Fashion retailers use bounding box annotation to automate product cropping for catalog images, detect items in user-generated content for shoppable posts, and identify outfit components in visual search queries. The technique is less precise than segmentation because the box includes background pixels around the garment, but it's fast enough to label thousands of images quickly when exact boundaries aren't required.
Polygon and Semantic Segmentation
Segmentation creates pixel-level masks that trace the exact outline of a garment. Polygon annotation uses connected points to define the shape, while semantic segmentation assigns a class label to every pixel in the image. A segmentation mask for a dress excludes the model's skin, the background wall, and any accessories not part of the garment. Only the fabric pixels get labeled.
This level of precision is required for virtual try-on systems, where the AI overlays a product onto a customer's uploaded photo. If the segmentation mask includes extra pixels, the overlay looks wrong. Segmentation also powers background removal tools that isolate products from studio backdrops for clean catalog images. The trade-off is time: segmentation takes three to five times longer than bounding box annotation because annotators must trace garment edges carefully.
Keypoint Annotation
Keypoint annotation marks specific structural points on a garment: collar tips, sleeve cuffs, waistline, hem edges, button placement. These points help AI models understand garment construction, which improves fit prediction and enables detailed product comparisons. A model trained on keypoint data can compare two dresses and flag that one has a higher waistline or longer sleeves, information that matters for fit recommendations.
Retailers use keypoint annotation for size estimation tools that predict whether a garment will fit based on the customer's measurements. The model measures distances between annotated keypoints to calculate proportions, then compares those proportions to the customer's body data. The accuracy of the fit recommendation depends on how consistently annotators placed keypoints across the training dataset.
Attribute Tagging
Attribute tagging labels visual characteristics beyond object class: color, pattern, fabric type, neckline, sleeve length, fit, occasion, and style. A single dress might get tagged with "floral print," "midi length," "V-neck," "short sleeves," "cotton," and "casual." These tags populate the filters customers use to narrow search results. Without attribute tags, a customer filtering for "long sleeve" would miss relevant products because the data isn't structured.
Fashion-specific attribute taxonomies can contain 150 or more labels. Annotators need training to apply them consistently. One annotator might call a color "navy," another "midnight blue." The taxonomy must define which label to use and provide visual examples. Attribute tagging feeds recommendation algorithms, improves search relevance, and enables cross-sell suggestions like "customers who bought this dress also bought these shoes."
Pro tip: Attribute tagging quality depends on examples, not just definitions. Your annotation spec should show visual references for every tag: what "oversized fit" looks like versus "relaxed fit," or "burnt orange" versus "rust." Without reference images, two annotators will interpret the same label differently, and your training data becomes inconsistent.
How Image Annotation Cuts Costs, Boosts Conversion, and Reduces Returns
Annotated product images drive measurable improvements across the customer journey. Fashion retailers using AI trained on quality annotation data report conversion lifts, reduced operational costs, and lower return rates compared to manual catalog management. The benefits compound as the annotated dataset grows and the models improve with more training examples.
Visual search conversion rates increase by 30 to 40 percent when powered by accurate annotation. Customers who upload a photo and find exactly what they're looking for convert at higher rates than those who type keywords and scroll through generic results. One Fortune 500 fashion retailer saw visual search account for 18 percent of total site traffic within six months of launch, with an average order value 22 percent higher than keyword search. The AI model behind that visual search was trained on 250,000 annotated product images covering 120 garment categories and 180 attribute labels.
Catalog automation cuts manual tagging costs by 50 to 70 percent. Instead of merchandisers manually writing descriptions and assigning category tags, AI models trained on annotated images generate metadata automatically. A product photo gets uploaded, the model detects the garment type, predicts attributes like color and sleeve length, and populates the product page with structured data. Human reviewers spot-check the output, but the bulk of the work happens without manual intervention. That speed matters when onboarding thousands of new SKUs per season.
Personalized recommendations improve when the AI understands visual similarity at the attribute level. A customer who clicks on three floral dresses should see more floral patterns, not just any dress. Recommendation engines trained on attribute-tagged images can surface visually similar products based on color, pattern, fit, and style. One mid-market retailer reported a 15 percent lift in click-through rate on recommended products after switching from keyword-based recommendations to a vision model trained on 180,000 annotated images with detailed attribute tags.
Return rates drop when fit prediction tools use models trained on keypoint and segmentation annotations. Virtual try-on features let customers see how a garment fits their body type before purchase, reducing fit-related returns. One global fashion platform reported a 25 percent reduction in return rates for products with virtual try-on enabled, compared to products without it. The feature relied on segmentation masks annotated at pixel-level accuracy, which took three months to produce for an initial dataset of 50,000 garment images.
Pro tip: Track annotation ROI with specific metrics tied to business outcomes. Measure visual search conversion rates, reduction in manual tagging hours, and return rate changes for products with AI-generated fit data. Annotation quality pays off when you can show the CFO that a $200K annotation project cut returns by 20 percent, saving $2M annually.
Development Process of AI Image Recognition Systems for Fashion E-commerce
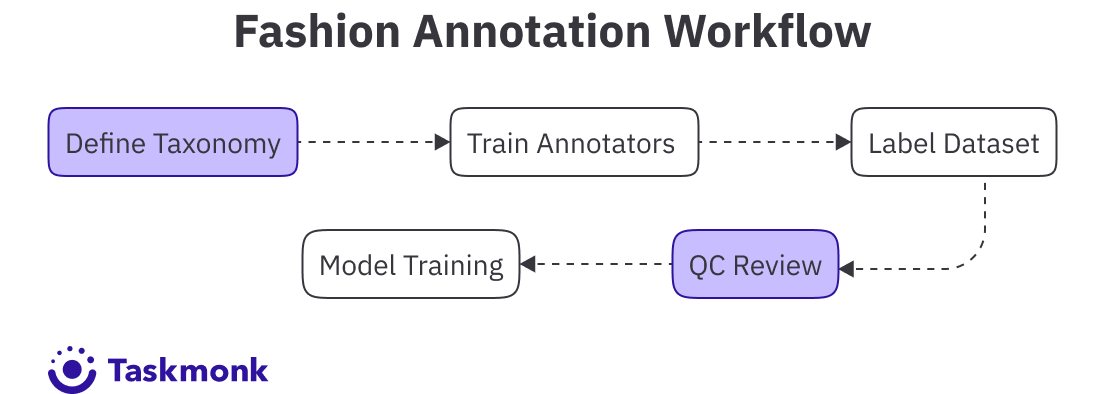
Building a production-ready image recognition system for fashion e-commerce requires more than just labeling images. Teams need to define a consistent taxonomy, train annotators on fashion-specific labeling rules, manage annotation workflows at scale, run quality assurance, and integrate the trained model into the product catalog pipeline. The development process typically follows five stages, with quality checkpoints at each step.
Taxonomy and Guidelines
The first step is defining what to label and how to label it. A fashion annotation taxonomy includes product categories (dress, jacket, pants, shoes, accessories), attribute labels (color, pattern, fabric, fit, neckline, sleeve type), and edge case rules for occluded garments, partial views, and mixed-material items. A mid-sized fashion catalog might require 80 product categories and 150 attribute labels. Each label needs a definition and visual examples so annotators apply it consistently.
Edge case rules prevent inconsistency when annotators encounter ambiguous images. If a model is wearing a sheer top over a camisole, does the annotator label one garment or two? If a jacket sleeve is partially hidden behind the model's back, does the sleeve length tag get applied or skipped? These decisions must be documented before annotation begins. Teams that skip this step find annotators making different choices on similar images, which introduces noise into the training data and degrades model performance.
Annotator Training
Fashion annotation requires domain knowledge that general-purpose annotation teams don't have. Annotators need to differentiate a bomber jacket from a varsity jacket, recognize a halter neckline versus a high neck, and identify fabric types like twill, crepe, or satin from visual texture alone. Training involves reviewing the taxonomy, studying visual examples for each label, and completing calibration tasks where annotators label a small batch and compare their output to gold-standard labels created by experts.
Inter-annotator agreement is the key metric during training. If two annotators label the same 100 images and their labels match 92 percent of the time, the taxonomy and training are working. If agreement drops below 85 percent, the taxonomy definitions need clarification or the annotators need more examples. Teams often run multiple calibration rounds before moving to full-scale annotation. The upfront investment in training prevents rework later when inconsistent labels cause model performance issues.
Annotation Workflow
Once annotators are trained, the dataset moves into production annotation. Images get assigned to annotators through a task management system that tracks progress, handles reviewer queues, and flags low-confidence labels for additional review. Teams typically use a maker-checker workflow where one annotator labels an image and a second annotator reviews the labels before approval. For high-stakes projects, a third reviewer samples 10 percent of approved images to catch systematic errors.
Annotation throughput varies by technique. Bounding box annotation for product detection runs at 500 to 800 images per hour per annotator. Semantic segmentation for virtual try-on drops to 100 to 150 images per hour because tracing garment edges pixel-by-pixel takes longer. Attribute tagging sits in the middle at 250 to 400 images per hour, depending on how many attributes each product requires. A 50,000-image dataset with bounding boxes and attribute tags might take four weeks with a team of 10 annotators working full-time.
Quality Assurance
QA catches annotation errors before they reach the training pipeline. Reviewers check for mislabeled products, incorrect attribute tags, and sloppy bounding boxes or segmentation masks. Automated checks flag obvious issues like bounding boxes that are too small, attribute combinations that aren't valid (a sleeveless dress tagged with "long sleeves"), or missing required labels. Human reviewers handle edge cases and ambiguous images where the rules aren't clear-cut.
Quality metrics include label accuracy (percentage of labels that match gold-standard examples), inter-annotator agreement (how often two annotators agree on the same image), and coverage (percentage of images that meet all labeling requirements). Fashion annotation projects typically target 95 percent accuracy and 90 percent inter-annotator agreement before releasing data for model training. Lower thresholds produce models that fail on edge cases or make inconsistent predictions.
Model Training and Iteration
Once the annotated dataset passes QA, it trains the computer vision model. The model learns to predict product categories, attributes, and bounding boxes based on the patterns in the training data. After training, the model gets evaluated on a held-out test set to measure accuracy. If performance is below target, the team investigates which labels the model struggles with and whether the training data needs more examples, clearer definitions, or better coverage of edge cases.
Iteration is normal. The first trained model rarely hits production accuracy targets. Teams add more annotated examples for underrepresented categories, refine the taxonomy to fix ambiguous labels, and retrain the model. One fashion retailer went through three annotation rounds before their visual search model reached 92 percent accuracy on actual customer uploads. Each round added 20,000 images with improved label consistency. The annotation work wasn't wasted, it was the iterative process that produced a production-ready model.
Impact of Fashion Image Annotation on Retail
Fashion retailers using annotation-powered AI see measurable improvements in conversion, operational efficiency, and customer satisfaction. The impact shows up in three areas: front-end customer experience, back-end catalog operations, and financial performance tied to reduced returns and increased basket size.
Visual search converts better than keyword search because customers find what they want faster. Shoppers who upload a photo and see relevant results in three seconds have a higher intent to purchase than those who type keywords and scroll through pages of generic results. One global fashion platform reported that visual search users had a 35 percent higher conversion rate and spent 18 percent more per order compared to keyword search users. The visual search feature was trained on 180,000 annotated product images covering garment types, colors, patterns, and style attributes.
Catalog automation reduces the time and cost of onboarding new products. Instead of merchandisers manually writing descriptions and tagging attributes for thousands of SKUs each season, AI models generate metadata automatically from product photos. One mid-market retailer cut catalog preparation time by 60 percent after deploying an annotation-trained model that predicted garment categories and attributes with 94 percent accuracy. The model processed 12,000 product images in two days, a task that previously took a team of eight merchandisers three weeks.
Return rates drop when customers get accurate fit predictions before purchase. Virtual try-on tools and size recommendation systems trained on keypoint and segmentation annotations show customers how a garment fits their body type, reducing the guesswork that leads to returns. One Fortune 500 fashion retailer reported a 22 percent reduction in return rates for products with AI-powered fit recommendations enabled. The feature was built on 75,000 annotated garment images with keypoint labels marking structural points like waistline, hem, and shoulder seams.
Personalization improves when the AI understands visual similarity beyond keywords. Recommendation engines that match customers with products based on attribute-level similarity drive higher engagement than simple category-based recommendations. A customer who clicks on floral midi dresses should see more floral prints in midi length, not just any dress. One e-commerce platform saw a 28 percent increase in recommendation click-through rate after switching from keyword matching to a vision model trained on 200,000 attribute-tagged product images.
How TaskMonk Handles Fashion Image Annotation for E-commerce
At Taskmonk, we noticed this early on, Fashion retailers scaling annotation projects face a common problem of maintaining label consistency across tens of thousands of images when the taxonomy is complex and edge cases are frequent. One mislabeled attribute or sloppy segmentation mask can degrade model performance, and fixing those errors after the dataset is complete is expensive. Teams need annotation infrastructure that enforces quality rules at the task level, not just at the review stage. That is where Taskmonk comes in:
Affinity-based annotator routing: TaskMonk routes annotation tasks to annotators based on demonstrated skill with specific product categories or attribute types. If an annotator consistently labels footwear with high accuracy, footwear tasks route to that annotator first. If another annotator excels at segmentation for sheer fabrics, those edge cases go to them. This domain matching reduces label errors on specialized product types that general annotators struggle with, like jewelry keypoints or patterned fabric attributes where texture and color overlap.
Three QC methods with configurable enforcement: TaskMonk supports Maker-Checker (one annotator labels, one reviewer approves), Maker-Editor (reviewer corrects labels instead of rejecting), and Majority Vote (three annotators label independently, system picks the most common label) as execution levels for QC. Fashion projects typically use Maker-Checker for standard product shots and Majority Vote for ambiguous images where annotators might disagree on fit or style classification. The platform enforces these workflows at the task level so no image bypasses review.
AI-assisted annotation for segmentation speed: Magic Wand and Super Pixel tools accelerate segmentation by auto-detecting garment boundaries based on color and pixel similarity. Annotators click on the garment and the tool generates a segmentation mask that traces the edges. The annotator refines the mask where the AI missed details, like sheer fabric or occluded sleeves. This cuts segmentation time from five minutes per image to two minutes without sacrificing pixel-level accuracy, which matters when a dataset requires 50,000 segmentation masks for virtual try-on training.
We don’t say all this in vain. TaskMonk has processed 480 million plus annotation tasks, supported 10 plus Fortune 500 teams, and holds a 4.6 out of 5 rating on G2.
If you need annotation infrastructure that scales with your fashion catalog and enforces quality without slowing throughput, book a demo with the TaskMonk team. They'll walk through your annotation requirements, show you how the QC workflows map to your taxonomy, and run a pilot batch so you can see label quality before committing to a full dataset.
Conclusion
Fashion retailers without annotation-trained AI are still writing product descriptions manually, losing visual search traffic to competitors, and accepting high return rates as the cost of doing business. The retailers who invested in annotation infrastructure three years ago are now processing 60 percent of their catalog automatically, converting visual search users at 35 percent higher rates, and seeing 20 to 25 percent drops in return rates for products with AI-powered fit recommendations. The gap widens every season as annotated datasets grow and models improve.
The teams that get annotation right build domain-specific taxonomies, train annotators on fashion terminology and edge case handling, and enforce quality workflows that catch label errors before they reach the training pipeline. They track annotation ROI with metrics tied to business outcomes: visual search conversion rates, catalog automation hours saved, return rate changes. They iterate on the training data when models underperform instead of assuming more volume will fix the problem.
Annotation quality sets the ceiling on everything downstream. A visual search feature is only as good as the training data behind it. A virtual try-on tool fails if the segmentation masks are sloppy. A recommendation engine suggests the wrong products if attribute tags are inconsistent. The work happens before the model trains, not after it ships.
.png)