■ Image annotation for drone and satellite imagery converts raw aerial captures into labeled training data for computer vision models. Without it, the data is just pixels.
■ The three annotation decisions that most affect model performance are tile size calibration, annotation type selection by task, and class boundary handling at scale.
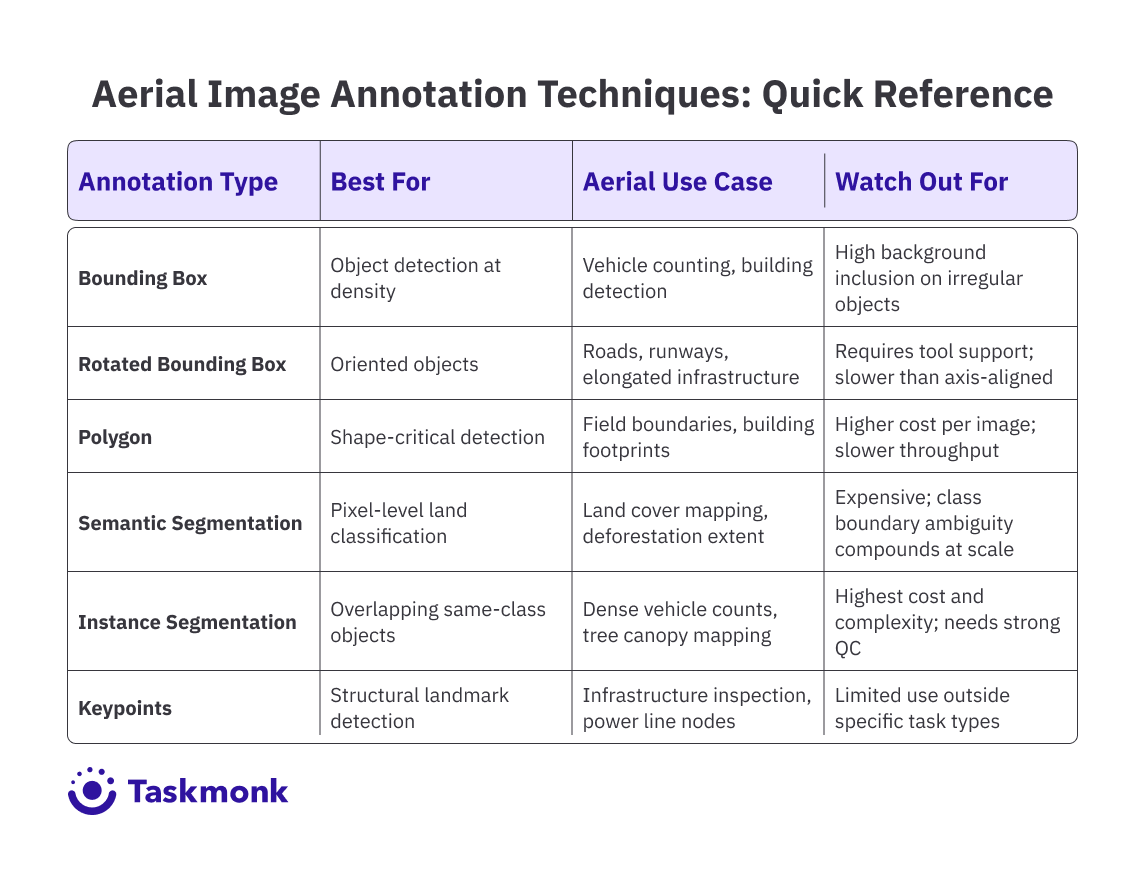
■ Bounding boxes suit high-density object detection; polygons and semantic segmentation are better for shape-critical tasks like field boundary mapping or land cover classification. Rotated boxes reduce noise on oriented objects like roads and runways.
■ Label drift in large aerial programs almost always comes from ambiguous spec rules, not annotator skill. Per-class inter-annotator agreement (IAA) tracking is the signal that catches it early.
■ Key industries using aerial annotation include precision agriculture, climate and carbon monitoring, disaster response, defence, and infrastructure inspection. Each has different error tolerance and QC requirements.
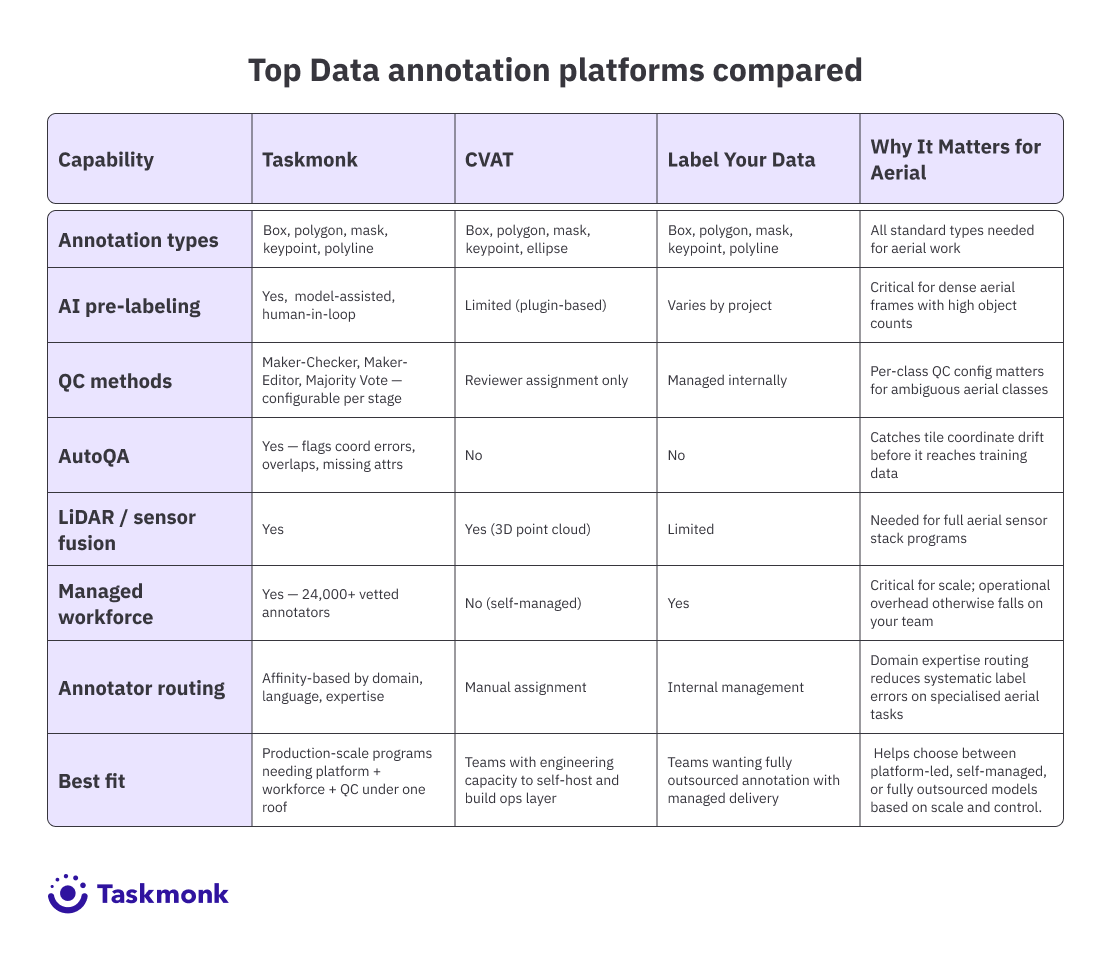
■ Taskmonk, CVAT, and Label Your Data are the main tool categories. The right choice depends on whether you need a platform only, a platform plus workforce, or a fully managed outsourced service.
Introduction
Your aerial detection model hits 91% precision on the holdout set. Then you deploy it on live drone footage from a different flight altitude, a different time of day, and a sensor that was not in your training corpus. Precision drops to 67%. The model did not break. Your training data was just narrower than you thought, because the annotation spec did not account for the variance in how your aerial data would actually look in production.
That gap is the core problem with image annotation for drone and satellite imagery. It is not a labeling volume problem. It is a label quality and spec design problem that shows up, depending on your business, as a delayed product release, a failed customer pilot, or a model that cannot hold up under real operating conditions.
Aerial data introduces distribution challenges that ground-level computer vision does not: altitude-dependent object scale, multi-spectral input channels, georeferenced coordinates that need to stay consistent across tiled images, and a density of small objects per frame that makes annotator consistency drift a real performance risk.
If you have worked through the fundamentals in Taskmonk'simage annotation guide, you already know that annotation quality sets the ceiling on model performance.
For aerial datasets, the distance between a well-designed annotation pipeline and a poorly designed one shows up directly in mAP, IoU consistency across classes, and how much rework you need after your first training run.
This article covers what is actually different about aerial annotation: the spec decisions that matter, the techniques that fit aerial data, how tools compare on the capabilities ML teams need, and where annotation quality problems in drone and satellite programs most commonly originate. Here is what you need to know.
What is Drone and Satellite Imagery Annotation?
Drone and satellite imagery annotation is the process of producing labeled ground truth from aerial captures so that computer vision models can learn to detect, classify, and segment objects and features as seen from above. The labeled output, whether bounding boxes, polygon masks, pixel-level semantic labels, or georeferenced polygons, becomes the training signal your model learns from.
What makes aerial annotation categorically different from ground-level annotation is the combination of altitude, scale ambiguity, and data modality. A vehicle detected at 200 meters looks nothing like the same vehicle in a street-level dataset. Its aspect ratio is compressed, its texture resolves to a handful of pixels, and it may be partially occluded by a shadow, an adjacent vehicle, or a tree canopy. The annotation spec has to define exactly how annotators handle each of these cases, because inconsistency in edge case handling is the primary source of label noise in aerial programs.
Satellite imagery adds its own layer of complexity. Images covering large geographic areas require tiling before annotation can begin, and tile boundaries introduce a specific risk: objects split across edges need consistent handling rules, or your model learns a spurious association between object truncation and tile position. Multi-spectral satellite data, combining RGB with near-infrared, short-wave infrared, or thermal bands, means annotators may be working with false-color composites that require domain training to interpret correctly.
At the model level, annotation quality in aerial datasets directly affects intersection over union (IoU) for detection and segmentation tasks, mean average precision (mAP) across classes, and how well the model generalizes to new flight conditions and sensor configurations. Annotation decisions made during dataset construction are the primary lever you control on all three.
Understanding the Annotation of Aerial Drones and Satellites Datasets
Though annotating aerial imagery looks like standard image labeling at a different angle, in practice, it’s where most model performance issues begin. Small choices in how you structure annotation tile size, annotation type, and how you define class boundaries can quietly introduce noise that no amount of model tuning can fix later.
This section breaks down the three decisions that matter most before your first batch goes into training.
1. Size calibration
The first is tile size calibration. Satellite images commonly run into the gigapixel range and need to be chipped into annotation-sized tiles before labeling can begin.
The tile dimensions you choose affect label quality in two directions:
Tiles that are too small strip annotators of the spatial context they need to resolve ambiguous objects
Tiles that are too large slow throughput and increase within-tile consistency variance as annotators lose track of their position.
For object detection tasks, a tile at least 3x the bounding box diameter of your smallest target class is a reliable starting rule. If your smallest target spans 20 pixels, a 64-pixel tile means annotators are regularly making label calls without enough surrounding context.
Pro tip:Set a minimum object size threshold in your annotation spec before labeling begins. For aerial datasets, objects below 10x10 pixels rarely provide usable training signal: the bounding box noise exceeds the object signal. Annotators who label these and annotators who skip them produce systematically different datasets, and the inconsistency is harder to correct after the fact than simply excluding sub-threshold objects from the spec upfront.
2. Selection of annotation type by task
The second decision is annotation type selection by task. The table below maps each annotation type to its aerial use case, strengths, and the failure mode to watch for at scale.
3. Handling of class boundary
The third decision is handling class boundary ambiguity at scale. In ground-level datasets, most objects have clear class membership. In satellite imagery, class boundaries are frequently contested: is this scrubland or degraded forest? Is this structure under construction or derelict? These are not edge cases in geospatial AI programs, they are a substantial proportion of real land cover and infrastructure datasets.
If the annotation spec does not define explicit decision rules for each ambiguous boundary, and the QC layer does not track inter-annotator agreement by class, that ambiguity resolves inconsistently across the annotator pool. The model learns a fuzzy, annotator-dependent boundary rather than a principled one, and you see it in precision-recall curves for the affected classes.
If your aerial model underperforms, check these first: tile context adequacy, annotation-type mismatch with task, and per-class IAA on ambiguous categories—these account for most dataset-induced errors.
Pro tip:Track inter-annotator agreement (IAA) by class, not just overall. Aggregate IAA on aerial datasets can look acceptable while masking severe disagreement on two or three ambiguous classes. Those specific classes are typically where your mAP is weakest, and they are invisible in aggregate QC reports. A per-class IAA breakdown after your calibration run tells you exactly where to tighten the spec before production volume begins.
Tools Used for Annotating Drone and Satellite Data
When it comes to choosing an annotation tool for aerial data, the emphasize should be less on feature checklists and more on how well it handles scale, complexity, and label consistency under real-world conditions. Unlike standard image datasets, aerial workflows introduce large image sizes, dense object distributions, and geospatial constraints that quickly expose limitations in tooling.
And therefore, the capabilities that matter most for aerial annotation tooling are:
Support for large image handling and tile workflows,
AI-assisted pre-labeling that reduces manual throughput bottlenecks on dense frames,
QC enforcement mechanisms that catch label inconsistency before it reaches training data, and
Export formats that integrate cleanly with your pipeline.
Most modern tools claim support for these capabilities. The real difference lies in how they implement them particularly under the scale, ambiguity, and structural complexity of aerial datasets.
Taskmonk
Taskmonk is designed for production-scale aerial annotation, where tooling needs to handle large imagery, dense object distributions, and strict consistency requirements without introducing downstream data issues. Instead of treating annotation as an isolated task, it structures the workflow as a controlled pipeline aligned to real-world ML requirements.
For aerial programs, its capabilities map directly to the four areas that determine annotation reliability at scale:
Large image handling and tile-based workflows
Satellite imagery often requires tiling before annotation, which introduces risks around coordinate drift and boundary inconsistencies. Taskmonk addresses this with validation layers that detect off-image annotations, boundary misalignment, and structural inconsistencies across tiles before they enter the dataset.
This ensures that annotations remain spatially consistent, critical for models that rely on georeferenced accuracy across large areas.
Model-assisted pre-labeling in dense scenes
Taskmonk uses model-assisted pre-labeling to seed annotations before human review. In dense aerial frames where each tile may contain dozens of objects, this reduces cold-start variance and speeds up convergence across annotators. Instead of drawing from scratch, annotators refine existing labels, leading to higher inter-annotator agreement and more consistent training data without increasing QC overhead.
Quality control enforcement at scale
Quality control is configurable at the pipeline level through Maker-Checker, Maker-Editor, and Majority Vote workflows.
For ambiguous aerial classes (e.g., land cover boundaries), Majority Vote surfaces disagreement early, preventing inconsistent labels from entering training data.
For high-confidence detection tasks, lighter QC layers maintain throughput while ensuring review coverage.
In addition, AutoQA flags structural errors such as overlapping masks, missing attributes, or invalid coordinates—that typically pass manual review but degrade dataset quality at scale.
Export formats and pipeline compatibility
Annotated outputs are structured to integrate directly with downstream ML pipelines, including support for geospatial formats where coordinate preservation is required. This reduces the need for post-processing and ensures that annotations remain aligned with model training requirements.
CVAT (Computer Vision Annotation Tool)
CVAT is the most established open-source annotation platform for production use, originally built by Intel and now maintained by the CVAT.ai team. It supports the annotation types aerial work requires: bounding boxes, polygons, polylines, points, ellipses, and segmentation masks. Workflow controls include task assignment, reviewer roles, and annotation versioning.
The practical constraint for geospatial AI companies scaling past their first few annotation programs is operational overhead. CVAT does not include built-in QC automation beyond reviewer assignment, managed annotator capacity, or enterprise compliance controls. Teams that have the engineering bandwidth to build the QC and workforce layer themselves will find it solid. Teams that need the annotation program to run reliably without dedicated internal ops will feel the gap.
Label Your Data
Label Your Data is a managed annotation service with documented coverage of drone and satellite imagery use cases, handling bounding boxes, semantic segmentation, polygons, keypoints, and polylines across agriculture, infrastructure, surveillance, and environmental programs.
As a fully managed service, they own annotator recruitment and QC within their workflow, which works well for companies that want to outsource the annotation program entirely.
The tradeoff is visibility: you get labeled output without direct control over QC configuration, annotator routing, or pipeline-level error tracking, which matters more as annotation programs grow in complexity and volume.
Industries Benefiting from Aerial Drones and Satellites Dataset Annotation
Aerial annotation requirements are not one size fits all. The way you design labels, define class boundaries, and enforce quality control depends heavily on the industry your model is built for.
The same annotation strategy that works for vehicle detection may fail when applied to crop health monitoring or carbon mapping.
Across geospatial AI use cases, annotation decisions are shaped as much by downstream business impact as by technical requirements—where label errors can translate directly into yield loss, compliance risk, delayed response times, or safety failures
Precision agriculture and crop monitoring.
Drone imagery, often captured across multiple spectral bands, is annotated to identify crop stress, disease, and irrigation issues. These labeled datasets train models that can detect problems earlier than traditional field inspections.
The challenge is that crop conditions don’t fall into clean categories. The difference between healthy, mildly stressed, and severely stressed crops is gradual, not clearly defined.
Because of this, annotation specs need clear threshold rules often based on spectral signals rather than just visible appearance to ensure consistency. These labeled datasets ultimately power crop intelligence platforms that farmers rely on for field-level decisions.
Climate and carbon monitoring.
Satellite image sequences over time are annotated to track deforestation, forest degradation, wetlands, and land use changes. These datasets train models used in carbon credit verification, biodiversity monitoring, and climate reporting.
The challenge is that these changes are often slow and spread across large areas. On top of that, satellite images can be affected by noise like clouds or atmospheric interference making real changes harder to detect.
Because of this, annotation accuracy is critical. For carbon market companies, a mislabeled forest boundary isn’t just a model error it can directly impact compliance and the credibility of carbon credits.
Disaster response and insurance
Before-and-after satellite images are annotated to identify structural damage, flood extent, and infrastructure disruption. These datasets train change detection models that help emergency responders and insurers assess damage much faster than ground surveys.
For insurance companies, accuracy is critical. Errors in estimating damage extent can delay claims processing and lead to incorrect loss calculations. As a result, annotation tolerance for mistakes is much lower than in most other applications.
Defense and surveillance
Aerial imagery is annotated to detect and classify vehicles, vessels, and critical installations. These datasets support intelligence analysis and automated surveillance systems.
The challenge is that many objects look similar from an aerial view, especially at high altitude. This makes accurate labeling dependent on domain expertise.
Because of the sensitivity of these applications, annotation programs require strict data handling and highly controlled workflows. Even small labeling errors can have serious downstream consequences, which is why quality standards and QC thresholds are much stricter than in most commercial use cases.
Infrastructure inspection
Drone footage is annotated to detect defects such as cracks, corrosion, and structural damage across assets like bridges, pylons, solar farms, and rooftops. These datasets train inspection models that reduce the need for risky and expensive manual inspections.
In this use case, accuracy is critical. Missing a defect like a crack means the model fails to flag a real safety issue.
As a result, quality control standards for infrastructure annotation are stricter than most other aerial applications, with very low tolerance for missed labels.
How Taskmonk Handles Drone and Satellite Annotation at Scale
The annotation problems that surface at scale in aerial programs are predictable. Label consistency drifts as annotator pools grow. QC bottlenecks develop when review throughput fails to keep pace with labeling volume.
Structural dataset errors, coordinate drift across tile boundaries, overlapping masks in dense frames, and missing attributes on ambiguous objects only become visible when model evaluation reveals them. By then, the fix is rework: re-labeling, re-training, delayed shipment.
Taskmonk is built to catch these before they compound.
By integrating pre-labeling, configurable QC workflows, and automated validation into each stage of the pipeline, Taskmonk prevents common aerial data issues from scaling into dataset-level failures. Here is how.
Pre-labeling that reduces cold-start variance.
For dense aerial frames, annotators starting from a blank approach the same complex tile differently, and that variance compounds across a large team. Taskmonk's model-assisted pre-labeling seeds annotations using trained models before human review.
The practical effect is not just throughput improvement, it is variance reduction: annotators correcting a pre-label converge faster than annotators drawing independently. Higher inter-annotator agreement on the same frames means cleaner training data with less QC overhead downstream.
QC configuration that fits aerial complexity.
In Taskmonk, the three enforcement methods, Maker-Checker, Maker-Editor, and Majority Vote, are configurable per pipeline stage rather than applied uniformly.
For satellite annotation where class boundaries are genuinely ambiguous, Majority Vote across multiple annotators surfaces disagreement before it becomes label noise.
For high-confidence drone object detection where throughput is the constraint, Maker-Checker maintains review coverage without reviewer bottlenecks. Running a tighter QC regime on your hardest classes without slowing the full program is what this flexibility enables.
AutoQA that catches aerial errors before they reach training data.
Taskmonk’s AutoQA further strengthens this by catching aerial-specific structural errors before they reach training data. Off-image coordinates in tiled satellite data, overlapping masks in dense drone footage, and missing required attributes often pass single-annotator review but still corrupt dataset geometry downstream.
AutoQA flags these automatically before tasks reach human review. For annotation programs running over months and millions of labeled objects, catching structural errors early is a program health question, not just a data quality one.
Affinity routing for domain-specific aerial tasks.
Interpreting near-infrared crop imagery, classifying land cover in arid or high-altitude terrain, or flagging infrastructure defects from altitude all require annotator domain knowledge that general labeling experience does not provide.
Taskmonk routes tasks to annotators with relevant expertise rather than distributing them across a general pool. For geospatial AI companies whose model accuracy is a product differentiator, annotator domain fit is a label quality lever, not an operational nicety.
Taskmonk has processed 480M+ tasks, logged 6M+ labeling hours, and holds a 4.6/5 rating on G2 across 10+ Fortune 500 programs. Reviewers specifically call out QC depth, annotator quality controls, and responsiveness as differentiating factors, which are the things that matter on a long-running aerial annotation program, not just a first batch.
If you are scoping an aerial annotation program and want to validate fit before committing,Taskmonk runs a 24 to 48-hour proof of concept on your actual data, delivering sample annotations, QC metrics, and versioned exports you can evaluate against your training pipeline before the program begins. That is a faster and lower-risk signal than a feature comparison spreadsheet.
Conclusion
Most aerial annotation programs don’t fail because of volume or tooling they fail because the annotation system wasn’t designed for real-world complexity. Edge cases were not defined upfront, inconsistencies slipped through QC, and feedback loops came too late resulting in re-labeling, re-training, and delayed releases.
The fix is not incremental; it’s foundational.
If you’re building geospatial AI models, treat annotation as a data engineering problem from day one. Define edge cases before labeling starts, enforce QC with measurable signals like per-class agreement, and validate your pipeline with calibration batches before scaling. These decisions determine whether your model holds up in production or breaks under real world conditions.
For teams working on precision agriculture, climate monitoring, or infrastructure intelligence, annotation quality is not a support function it’s the layer where model reliability is decided.
If you’re planning an aerial annotation program, validate your approach early. Run a pilot on real data, test your QC assumptions, and ensure your pipeline can handle scale before committing to full production.
FAQs
What annotation types work best for drone imagery object detection?
It depends on object density and shape regularity. Axis-aligned bounding boxes are fast and sufficient when objects are compact and isolated. For dense aerial scenes where boxes include significant background, rotated bounding boxes reduce noise on oriented objects like vehicles and elongated infrastructure. Polygons are the right call when object shape affects downstream task accuracy, such as building footprint extraction or field boundary mapping. Mixing annotation types within a dataset for the same class creates systematic inconsistency: pick the type that fits your hardest cases and apply it uniformly.
How does tile size affect annotation quality in satellite imagery programs?
Tile size is a tradeoff between annotator context and throughput. Tiles that are too small strip the spatial context that annotators need to resolve edge cases and produce more label errors at object boundaries. Tiles that are too large slow per-task annotation time and increase within-tile consistency variance. A practical starting point: tile size should be at least 3x the bounding box diameter of your smallest target class. For programs with multiple target scales, such as both buildings and vehicles in the same dataset, consider separate tile configurations per annotation pass rather than a single tile size that underserves both.
What causes label drift in large aerial annotation programs, and how do you prevent it?
Label drift comes from three sources: annotator turnover, bringing in people who were not in the original calibration run; spec ambiguity that resolves differently as annotators encounter novel edge cases; and growing annotator pools, where new people develop their own interpretation of ambiguous guidelines. Prevention requires active management: run periodic calibration batches with ground-truth tasks on your hardest classes, track per-annotator IAA over time, and treat spec updates as formal events with re-calibration for the affected annotator pool, not just a changelog update.
How do you handle multi-spectral satellite imagery annotation?
Annotators working on multi-spectral data need explicit training on interpreting the specific band combination they are working with. False-colour composites using near-infrared look nothing like RGB imagery, and annotators without domain training make systematic class errors that are hard to detect in QC because the errors are internally consistent. Build your annotation spec around the specific band combination your model trains on. If your program uses multiple band combinations across data sources, maintain separate specs for each and do not mix labeled data across configurations without explicit normalization.
Can automated pre-labeling be used reliably for aerial annotation?
For high-confidence, well-defined object classes where you have a trained model, yes, and the throughput gains on dense aerial frames are significant. For novel classes, ambiguous land cover boundaries, or edge cases outside your pre-labeling model's training distribution, automated suggestions introduce systematic errors that annotators tend to accept rather than correct, because correction requires more judgment than the original annotation task. Monitor pre-label acceptance rates by class: if annotators are accepting more than 85% of suggestions without modification on a genuinely complex class, the pre-label quality probably does not warrant that acceptance rate and you are building a false-confidence dataset.
.png)