We did the heavy lifting in 2025. Here’s what it
added up to ->
View Details.
Collect, evaluate, and govern the datasets that make LLMs and agents work
—preference rankings, agent traces, RAG grounding with citations, and red-teaming, delivered with measurable quality, lineage, and enterprise-grade controls.
TALK TO OUR EXPERTS
Advanced features for LLM & AI agent data operations
Generate preference data, label AI agent traces, evaluate responses, and govern quality on one platform.
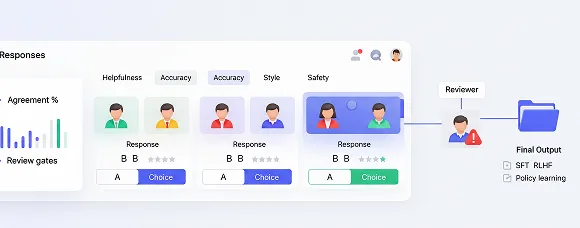
Preference & ranking datasets
Generate calibrated point-wise and pairwise judgments with rubrics for helpfulness, accuracy, style, and safety. Track disagreement and inter-annotator agreement, enforce review gates, and export tidy splits for SFT, RLHF, or policy learning.

Evaluation & guardrails at scale
Score hallucinations, missing citations, PII/regulated content, toxicity, bias, and jailbreak susceptibility. Run red-team campaigns, track issue classes, and quantify improvements as you iterate prompts, models, or guardrails.
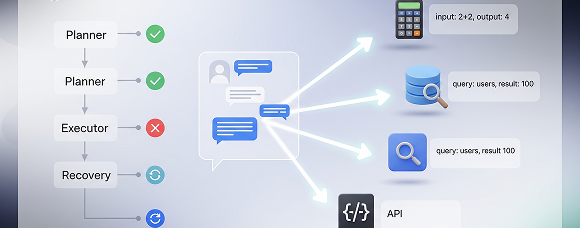
Agent & tool-use trace data
Label multi-turn conversations, function calls, tool arguments, and results, including planner-executor steps and recovery attempts. Capture reasons and outcomes to teach reliable tool selection, argument formatting, and failure handling in production agents.
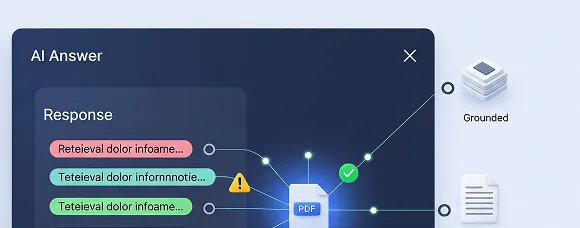
RAG grounding & citation checks
Score retrieval quality, source coverage, and grounding strength. Link claims to citations, mark unsupported spans, and categorize error types, enabling measurable improvements to chunking, retrieval, and answer synthesis across knowledge updates.

Data QA, Metrics & Lineage
Apply gold tasks, consensus, and blind checks; monitor scorer drift and backlog health. Tie dataset quality to model metrics, maintain versioned guidelines, and preserve complete lineage from raw input to final export.
.webp)
APIs, webhooks & storage integrations
Connect your data lake or buckets, trigger jobs via API, and stream exports to training pipelines. Keep everything auditable with roles, SSO/SAML, and change logs.
Use cases for LLMs & agentic AI
From instruction-tuning to production guardrails, Taskmonk keeps your data ops tight, testable, and compliant.

Instruction tuning datasets
Curate instruction–response pairs that emphasize edge cases and disambiguation, scored with rubrics for helpfulness, correctness, and tone. Version examples, track reviewer alignment, and export balanced splits optimized for SFT and continual updates.

RLHF/RLAIF preference data
Produce point-wise and pairwise judgments with calibrated scorer programs and gold tasks. Monitor inter-annotator agreement, analyze disagreement patterns, and shape reward models or AI-feedback loops without sacrificing auditability or bias controls.

Evaluation for chat, Q&A, and summarization
Build test sets that measure helpfulness, factual accuracy, style adherence, latency impacts, and safety. Tag error classes, set acceptance thresholds, and detect regressions before rolling model or prompt changes into production.

RAG grounding & retrieval quality
Label retrieval quality, coverage, and source fidelity. Link claims to citations at span level, flag unsupported content, and quantify grounding strength to tune chunking, re-ranking, and synthesis with defensible, versioned evidence.

Agent/tool-use traces
Annotate function calls, arguments, tool outputs, planner–executor steps, and recovery attempts. Capture outcomes to teach reliable tool selection, argument formatting, and fallback behaviors for agents that must handle real-world failure modes.

Safety red teaming
Generate adversarial prompts and evaluate responses for PII, toxicity, jailbreaks, bias, and policy non-compliance. Triage by severity, attach exemplars, and quantify mitigation impact across releases and guardrail updates with clear audit trails.
Instruction tuning datasets
Curate instruction–response pairs that emphasize edge cases and disambiguation, scored with rubrics for helpfulness, correctness, and tone. Version examples, track reviewer alignment, and export balanced splits optimized for SFT and continual updates.
RLHF/RLAIF preference data
Produce point-wise and pairwise judgments with calibrated scorer programs and gold tasks. Monitor inter-annotator agreement, analyze disagreement patterns, and shape reward models or AI-feedback loops without sacrificing auditability or bias controls.
Evaluation for chat, Q&A, and summarization
Build test sets that measure helpfulness, factual accuracy, style adherence, latency impacts, and safety. Tag error classes, set acceptance thresholds, and detect regressions before rolling model or prompt changes into production.
RAG grounding & retrieval quality
Label retrieval quality, coverage, and source fidelity. Link claims to citations at span level, flag unsupported content, and quantify grounding strength to tune chunking, re-ranking, and synthesis with defensible, versioned evidence.
Agent/tool-use traces
Annotate function calls, arguments, tool outputs, planner–executor steps, and recovery attempts. Capture outcomes to teach reliable tool selection, argument formatting, and fallback behaviors for agents that must handle real-world failure modes.
Safety red teaming
Generate adversarial prompts and evaluate responses for PII, toxicity, jailbreaks, bias, and policy non-compliance. Triage by severity, attach exemplars, and quantify mitigation impact across releases and guardrail updates with clear audit trails.
Instruction tuning datasets
Curate instruction–response pairs that emphasize edge cases and disambiguation, scored with rubrics for helpfulness, correctness, and tone. Version examples, track reviewer alignment, and export balanced splits optimized for SFT and continual updates.
RLHF/RLAIF preference data
Produce point-wise and pairwise judgments with calibrated scorer programs and gold tasks. Monitor inter-annotator agreement, analyze disagreement patterns, and shape reward models or AI-feedback loops without sacrificing auditability or bias controls.
Evaluation for chat, Q&A, and summarization
Build test sets that measure helpfulness, factual accuracy, style adherence, latency impacts, and safety. Tag error classes, set acceptance thresholds, and detect regressions before rolling model or prompt changes into production.
RAG grounding & retrieval quality
Label retrieval quality, coverage, and source fidelity. Link claims to citations at span level, flag unsupported content, and quantify grounding strength to tune chunking, re-ranking, and synthesis with defensible, versioned evidence.
Agent/tool-use traces
Annotate function calls, arguments, tool outputs, planner–executor steps, and recovery attempts. Capture outcomes to teach reliable tool selection, argument formatting, and fallback behaviors for agents that must handle real-world failure modes.
Safety red teaming
Generate adversarial prompts and evaluate responses for PII, toxicity, jailbreaks, bias, and policy non-compliance. Triage by severity, attach exemplars, and quantify mitigation impact across releases and guardrail updates with clear audit trails.
Instruction tuning datasets
Curate instruction–response pairs that emphasize edge cases and disambiguation, scored with rubrics for helpfulness, correctness, and tone. Version examples, track reviewer alignment, and export balanced splits optimized for SFT and continual updates.
RLHF/RLAIF preference data
Produce point-wise and pairwise judgments with calibrated scorer programs and gold tasks. Monitor inter-annotator agreement, analyze disagreement patterns, and shape reward models or AI-feedback loops without sacrificing auditability or bias controls.
Evaluation for chat, Q&A, and summarization
Build test sets that measure helpfulness, factual accuracy, style adherence, latency impacts, and safety. Tag error classes, set acceptance thresholds, and detect regressions before rolling model or prompt changes into production.
RAG grounding & retrieval quality
Label retrieval quality, coverage, and source fidelity. Link claims to citations at span level, flag unsupported content, and quantify grounding strength to tune chunking, re-ranking, and synthesis with defensible, versioned evidence.
Agent/tool-use traces
Annotate function calls, arguments, tool outputs, planner–executor steps, and recovery attempts. Capture outcomes to teach reliable tool selection, argument formatting, and fallback behaviors for agents that must handle real-world failure modes.
Safety red teaming
Generate adversarial prompts and evaluate responses for PII, toxicity, jailbreaks, bias, and policy non-compliance. Triage by severity, attach exemplars, and quantify mitigation impact across releases and guardrail updates with clear audit trails.
Instruction tuning datasets
Curate instruction–response pairs that emphasize edge cases and disambiguation, scored with rubrics for helpfulness, correctness, and tone. Version examples, track reviewer alignment, and export balanced splits optimized for SFT and continual updates.
RLHF/RLAIF preference data
Produce point-wise and pairwise judgments with calibrated scorer programs and gold tasks. Monitor inter-annotator agreement, analyze disagreement patterns, and shape reward models or AI-feedback loops without sacrificing auditability or bias controls.
Evaluation for chat, Q&A, and summarization
Build test sets that measure helpfulness, factual accuracy, style adherence, latency impacts, and safety. Tag error classes, set acceptance thresholds, and detect regressions before rolling model or prompt changes into production.
RAG grounding & retrieval quality
Label retrieval quality, coverage, and source fidelity. Link claims to citations at span level, flag unsupported content, and quantify grounding strength to tune chunking, re-ranking, and synthesis with defensible, versioned evidence.
Agent/tool-use traces
Annotate function calls, arguments, tool outputs, planner–executor steps, and recovery attempts. Capture outcomes to teach reliable tool selection, argument formatting, and fallback behaviors for agents that must handle real-world failure modes.
Safety red teaming
Generate adversarial prompts and evaluate responses for PII, toxicity, jailbreaks, bias, and policy non-compliance. Triage by severity, attach exemplars, and quantify mitigation impact across releases and guardrail updates with clear audit trails.
A governed data pipeline your AI team can trust
Design, automate, and audit every step, from raw text to export-ready datasets.

Design
Define rubrics, exemplars, and gold tasks; specify sampling, acceptance thresholds, and error classes. Version guidelines, attach lineage to every record, and make your rubric the single source of truth.

Execute
Operationalize annotate → review → consensus → sign-off with skill-based routing and SLAs. Use assisted labeling and scorer training; resolve disagreements with retries—preserving throughput without masking quality issues.

Audit
Monitor accuracy, IAA, and scorer drift with dashboards. Inspect confusion matrices and regression flags, trace any label to guideline version and reviewer actions, and export audit packs your risk teams can verify.

Automate & integrate
Connect buckets and pipelines via APIs/webhooks. Enforce retention and egress policies, trigger rebuilds when datasets change, and ship versioned, manifest-based exports straight into training/eval jobs.
Design
Define rubrics, exemplars, and gold tasks; specify sampling, acceptance thresholds, and error classes. Version guidelines, attach lineage to every record, and make your rubric the single source of truth.
Execute
Operationalize annotate → review → consensus → sign-off with skill-based routing and SLAs. Use assisted labeling and scorer training; resolve disagreements with retries—preserving throughput without masking quality issues.
Audit
Monitor accuracy, IAA, and scorer drift with dashboards. Inspect confusion matrices and regression flags, trace any label to guideline version and reviewer actions, and export audit packs your risk teams can verify.
Automate & integrate
Connect buckets and pipelines via APIs/webhooks. Enforce retention and egress policies, trigger rebuilds when datasets change, and ship versioned, manifest-based exports straight into training/eval jobs.
Enterprise-grade security for LLM & agent data
.svg)
Identity & access control
SSO/SAML, SCIM provisioning, RBAC with least-privilege, scoped API tokens, IP allowlists, and time-bound elevation with approvals plus complete session logging.

Keys & encryption
Customer-managed keys (KMS), envelope encryption, TLS 1.2+, automatic key rotation, secrets vaulting, and integrity checks/watermarking on exports.
.svg)
Audit & compliance
Immutable audit logs and dataset lineage, retention/egress policies, change-management workflows, and SOC 2/GDPR-aligned evidence packs your security and risk teams can verify.
.png)
Identity & access control
SSO/SAML, SCIM provisioning, RBAC with least-privilege, scoped API tokens, IP allowlists, and time-bound elevation with approvals plus complete session logging.

Keys & encryption
Customer-managed keys (KMS), envelope encryption, TLS 1.2+, automatic key rotation, secrets vaulting, and integrity checks/watermarking on exports.
.png)
Audit & compliance
Immutable audit logs and dataset lineage, retention/egress policies, change-management workflows, and SOC 2/GDPR-aligned evidence packs your security and risk teams can verify.
Protect sensitive corpora and agent logs without slowing delivery.
TALK TO OUR EXPERTS
Why Taskmonk’s AI data platform for LLM & agent data operations
Proven at scale
Handle high-volume programs with predictable SLAs and elastic capacity. We deliver governed datasets with scorer calibration, disagreement analysis, and audit-ready lineage
Built for production
Operate large programs with predictable SLAs. Templates for preference ranking, RAG grounding, and agent traces compress setup time while elastic capacity scales reviewers without sacrificing rubric adherence.
Measurable quality
Quality gates tie dataset signals to model KPIs—factuality, helpfulness, safety. Dashboards surface disagreement patterns and drift early, cutting regressions and speeding pre-prod acceptance.
Transparent delivery
Weekly QA reports, acceptance criteria, and complete lineage per export. You always know who labeled what, under which guideline, and why it passed review.
Proven at scale
Handle high-volume programs with predictable SLAs and elastic capacity. We deliver governed datasets with scorer calibration, disagreement analysis, and audit-ready lineage
Built for production
Operate large programs with predictable SLAs. Templates for preference ranking, RAG grounding, and agent traces compress setup time while elastic capacity scales reviewers without sacrificing rubric adherence.
Measurable quality
Quality gates tie dataset signals to model KPIs—factuality, helpfulness, safety. Dashboards surface disagreement patterns and drift early, cutting regressions and speeding pre-prod acceptance.
Transparent delivery
Weekly QA reports, acceptance criteria, and complete lineage per export. You always know who labeled what, under which guideline, and why it passed review.
Expert data labeling services for LLMs & agents
When you need people plus platform, we deliver governed datasets—not just completed tasks backed by lineage, SLAs, and audits.
TALK TO OUR EXPERTS
End-to-end project management
Scope datasets, define rubrics and gold tasks, stand up workflows, and run QA to delivery. One owner, weekly SLAs, transparent dashboards, and audit packs your security and risk teams can review independently.
Specialist reviewer pools
Calibrated evaluators for preference ranking, RAG citations, red-team scoring, and agent/tool-use traces. We train with exemplars, measure IAA, and monitor scorer drift to keep signals consistent across releases.
Secure delivery options
Run projects in your cloud with private networking, VPC isolation, and customer-managed keys. Enforce data residency and retention, restrict egress, and use cleared reviewers.
Flexible engagement models
Start with a pilot, expand to sustained programs, or burst for backfills. Pricing is transparent—per task or hour—with quality gates tied to acceptance criteria, not just throughput.
End-to-end project management
Scope datasets, define rubrics and gold tasks, stand up workflows, and run QA to delivery. One owner, weekly SLAs, transparent dashboards, and audit packs your security and risk teams can review independently.
Specialist reviewer pools
Calibrated evaluators for preference ranking, RAG citations, red-team scoring, and agent/tool-use traces. We train with exemplars, measure IAA, and monitor scorer drift to keep signals consistent across releases.
Secure delivery options
Run projects in your cloud with private networking, VPC isolation, and customer-managed keys. Enforce data residency and retention, restrict egress, and use cleared reviewers.
Flexible engagement models
Start with a pilot, expand to sustained programs, or burst for backfills. Pricing is transparent—per task or hour—with quality gates tied to acceptance criteria, not just throughput.
FAQ
What is LLM data labeling, and how is it different from generic annotation?
LLM data labeling targets instruction–response pairs, preference ranking (pointwise/pairwise), multi-turn conversation scoring, agent/tool-use traces, and RAG grounding, purpose-built for LLM evaluation and RLHF/RLAIF. It relies on rubric-based judgments (helpfulness, correctness, style, safety), span-level citation linking, and dataset lineage so models can be fine-tuned, aligned, and audited. Generic annotation (e.g., image tags) lacks the structure and evidence needed to govern large language models in production.
What quality controls ensure reliable LLM evaluation datasets?
Quality ops combine gold tasks, scorer calibration, consensus/spot-check review, and inter-annotator agreement (IAA) monitoring. We measure scorer drift, disagreement patterns, and bias indicators, then update rubrics and exemplars when thresholds are breached. Every label carries provenance—guideline version, reviewer ID (pseudonymized), timestamps—so audits and root-cause analysis are straightforward, and LLM evaluation datasets remain stable across releases.
How do you protect sensitive model data and agent logs during labeling?
Security controls include SOC 2–aligned practices, GDPR-aware processing, SSO/SAML, role-based access, customer-managed keys, encryption in transit/at rest, and VPC/private networking. PII redaction at ingestion, least-privilege access, retention policies, and egress restrictions keep datasets governed. Full audit logs and export watermarking preserve evidence for compliance reviews without slowing developer velocity.
What integrations and export formats are available, and how fast can we pilot?
Connect via APIs/webhooks and write directly to S3/GCS/Azure. Export JSONL/CSV or custom schemas with versioned rubrics and dataset lineage. Most pilots start in days: import a sample, calibrate reviewers, return a QA-scored dataset, and iterate. When you need people plus platform, our AI services platform can staff calibrated reviewers under your SLAs.
How to detect hallucinations and evaluate RAG grounding with citations?
We run span-level factuality evaluation with citation linking: each claim ties to a source snippet; unsupported spans are flagged. Datasets track retrieval quality, source coverage, grounding strength, and error classes (unsupported, outdated, misattributed). You set acceptance thresholds; dashboards catch regressions as prompts/models change, so RAG, re-ranking, and chunking can be tuned with defensible, auditable evidence.
High-signal datasets for LLMs & agents—preference, tool-use traces, grounded citations, safety-governed and export-ready.