We did the heavy lifting in 2025. Here’s what it
added up to ->
View Details.
Curate and label multimodal data like Image, Video, Text, Audio, DICOM, PDFs, and Sensor data in one secure platform.
Model-assisted workflows, human review, and SLAs that keep launches on schedule.
TALK TO OUR EXPERTS
Features that keep multimodal data programs moving
One system to index, label, verify, and ship multimodal data—across images, video, text, audio, PDFs, and sensors.

Curation & search
Index multimodal files across S3/GCS/Azure and surface the exact subset fast. Search multimodal files in seconds using metadata, attribute filters, embeddings, and natural-language search. Deduplicate, stratify, and sample to export precise slices for evaluation and training.
.webp)
Model-assisted labeling
Plug in your or commercial AI models for pre-labels and flags. Use OCR for documents, ASR for audio, and keyframe-tracked/interpolation for video. Taskmonk experts verify and sign off labels for model training.

Multimodal dataset organization
Understand and organize large complex datasets easily. Version datasets with validation, test splits, and lineage. Link images, video, text, audio, and documents. Track label distribution & drift, and publish multimodal dataset for reproducible training.

Workflow & QA
Build multimodal annotation, review, and consensus workflows without code. Execution levels on Taskmonk enforce pass criteria, route disagreements to reviewers, track agreement, precision and recall, and export qualified batches for training
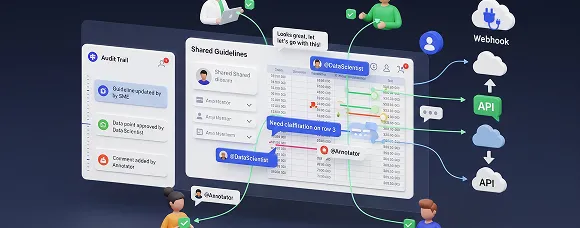
Collaboration and integrations
Keep data scientists, annotators, and SMEs aligned with shared guidelines, examples, and task comments. Assign reviewers, mention for clarifications, and track decisions in the audit trail. Connect datasets via APIs and webhooks.

Security, governance & compliance
Enterprise controls by default: SSO/SAML, RBAC, encryption in transit and at rest, audit logs. Deploy in your VPC, use signed URLs for access, enforce least privilege, retention, and data residency policies.
Multimodal data labeling, enterprise-grade, for any use case
Run workflows on our platform or with Taskmonk experts. Start fast, keep quality measurable, and ship reliably.

Vision and language
Link phrases to boxes or polygons on images and video frames. Capture answers with evidence regions and frame IDs. Export audit-ready datasets for captioning, referring expressions, and VQA, including labeled failure cases for evaluation.

Ecommerce product data
Match images to SKUs and pull attributes from titles and specs. Normalize taxonomy, flag missing fields, and add language variants so product pages stay consistent and searchable.

Speech analytics
Transcribe audio, split speakers, and timestamp phrases. Label intents, sentiment, and sensitive content for redaction, then export segment-level datasets ready for classifier training.

LiDAR & geospatial
Annotate boxes, keypoints, and masks on multi-camera video and align labels to LiDAR point clouds and maps. Track objects across frames with keyframe interpolation and export time-aligned training sets.

Healthcare imaging
Label findings on studies under governed access and link report text to image evidence. Export de-identified ground truth with full audit trails for review and compliance.

Human evaluation, RLHF & RAG
Run preference ranking, rubric-based scoring, and error tagging across images, video, text, and audio. Check retrieval answers against source spans and page coordinates. Export preferences, scores, and rationales for alignment and fine-tuning.
Vision and language
Link phrases to boxes or polygons on images and video frames. Capture answers with evidence regions and frame IDs. Export audit-ready datasets for captioning, referring expressions, and VQA, including labeled failure cases for evaluation.
Ecommerce product data
Match images to SKUs and pull attributes from titles and specs. Normalize taxonomy, flag missing fields, and add language variants so product pages stay consistent and searchable.
Speech analytics
Transcribe audio, split speakers, and timestamp phrases. Label intents, sentiment, and sensitive content for redaction, then export segment-level datasets ready for classifier training.
LiDAR & geospatial
Annotate boxes, keypoints, and masks on multi-camera video and align labels to LiDAR point clouds and maps. Track objects across frames with keyframe interpolation and export time-aligned training sets.
Healthcare imaging
Label findings on studies under governed access and link report text to image evidence. Export de-identified ground truth with full audit trails for review and compliance.
Human evaluation, RLHF & RAG
Run preference ranking, rubric-based scoring, and error tagging across images, video, text, and audio. Check retrieval answers against source spans and page coordinates. Export preferences, scores, and rationales for alignment and fine-tuning.
Vision and language
Link phrases to boxes or polygons on images and video frames. Capture answers with evidence regions and frame IDs. Export audit-ready datasets for captioning, referring expressions, and VQA, including labeled failure cases for evaluation.
Ecommerce product data
Match images to SKUs and pull attributes from titles and specs. Normalize taxonomy, flag missing fields, and add language variants so product pages stay consistent and searchable.
Speech analytics
Transcribe audio, split speakers, and timestamp phrases. Label intents, sentiment, and sensitive content for redaction, then export segment-level datasets ready for classifier training.
LiDAR & geospatial
Annotate boxes, keypoints, and masks on multi-camera video and align labels to LiDAR point clouds and maps. Track objects across frames with keyframe interpolation and export time-aligned training sets.
Healthcare imaging
Label findings on studies under governed access and link report text to image evidence. Export de-identified ground truth with full audit trails for review and compliance.
Human evaluation, RLHF & RAG
Run preference ranking, rubric-based scoring, and error tagging across images, video, text, and audio. Check retrieval answers against source spans and page coordinates. Export preferences, scores, and rationales for alignment and fine-tuning.
Vision and language
Link phrases to boxes or polygons on images and video frames. Capture answers with evidence regions and frame IDs. Export audit-ready datasets for captioning, referring expressions, and VQA, including labeled failure cases for evaluation.
Ecommerce product data
Match images to SKUs and pull attributes from titles and specs. Normalize taxonomy, flag missing fields, and add language variants so product pages stay consistent and searchable.
Speech analytics
Transcribe audio, split speakers, and timestamp phrases. Label intents, sentiment, and sensitive content for redaction, then export segment-level datasets ready for classifier training.
LiDAR & geospatial
Annotate boxes, keypoints, and masks on multi-camera video and align labels to LiDAR point clouds and maps. Track objects across frames with keyframe interpolation and export time-aligned training sets.
Healthcare imaging
Label findings on studies under governed access and link report text to image evidence. Export de-identified ground truth with full audit trails for review and compliance.
Human evaluation, RLHF & RAG
Run preference ranking, rubric-based scoring, and error tagging across images, video, text, and audio. Check retrieval answers against source spans and page coordinates. Export preferences, scores, and rationales for alignment and fine-tuning.
Vision and language
Link phrases to boxes or polygons on images and video frames. Capture answers with evidence regions and frame IDs. Export audit-ready datasets for captioning, referring expressions, and VQA, including labeled failure cases for evaluation.
Ecommerce product data
Match images to SKUs and pull attributes from titles and specs. Normalize taxonomy, flag missing fields, and add language variants so product pages stay consistent and searchable.
Speech analytics
Transcribe audio, split speakers, and timestamp phrases. Label intents, sentiment, and sensitive content for redaction, then export segment-level datasets ready for classifier training.
LiDAR & geospatial
Annotate boxes, keypoints, and masks on multi-camera video and align labels to LiDAR point clouds and maps. Track objects across frames with keyframe interpolation and export time-aligned training sets.
Healthcare imaging
Label findings on studies under governed access and link report text to image evidence. Export de-identified ground truth with full audit trails for review and compliance.
Human evaluation, RLHF & RAG
Run preference ranking, rubric-based scoring, and error tagging across images, video, text, and audio. Check retrieval answers against source spans and page coordinates. Export preferences, scores, and rationales for alignment and fine-tuning.
Workflows for effective multimodal data pipeline

Build effective workflows
Define tasks, roles, routing, and pass criteria. Configure Annotate → Review → Consensus without code. Lock instructions to a version and assign skills and SLAs so work lands with the right people.

Label, review, adjudicate
Start with pre-labels and confidence flags. Use keyframe tracking for video and OCR/ASR for documents and audio. Disagreements move to an adjudicator. Execution levels stop batches that miss quality thresholds.
.svg)
Audit and export
Every action is time-stamped and searchable. Schedule exports to S3, GCS, or Azure in JSONL, COCO, YOLO, CSV, or your format. Datasets stay versioned and reproducible.
Build effective workflows
Define tasks, roles, routing, and pass criteria. Configure Annotate → Review → Consensus without code. Lock instructions to a version and assign skills and SLAs so work lands with the right people.
Label, review, adjudicate
Start with pre-labels and confidence flags. Use keyframe tracking for video and OCR/ASR for documents and audio. Disagreements move to an adjudicator. Execution levels stop batches that miss quality thresholds.
Audit and export
Every action is time-stamped and searchable. Schedule exports to S3, GCS, or Azure in JSONL, COCO, YOLO, CSV, or your format. Datasets stay versioned and reproducible.
Build the steps once. Enforce checks automatically. Keep handoffs smooth.
TALK TO OUR EXPERTS
Secure multimodal workflows at scale

Enterprise-grade security
SSO/SAML, role-based access, and encryption in transit and at rest. Fine-grained permissions, device and session policies, IP allowlists, and full audit logs with who/when/what for every action.


Compliance built-in
SOC 2, HIPAA, and GDPR alignment. Data residency and retention controls. Least-privilege access, PII/PHI redaction where required, and complete traceability for internal reviews and regulators.

Flexible deployment
Run in your VPC and region or connect SaaS via short-lived signed URLs. Originals stay in your S3/GCS/Azure buckets. The platform stores labels, metrics, and logs with optional private networking and region pinning.
Enterprise-grade security
SSO/SAML, role-based access, and encryption in transit and at rest. Fine-grained permissions, device and session policies, IP allowlists, and full audit logs with who/when/what for every action.
Compliance built-in
SOC 2, HIPAA, and GDPR alignment. Data residency and retention controls. Least-privilege access, PII/PHI redaction where required, and complete traceability for internal reviews and regulators.
Flexible deployment
Run in your VPC and region or connect SaaS via short-lived signed URLs. Originals stay in your S3/GCS/Azure buckets. The platform stores labels, metrics, and logs with optional private networking and region pinning.
Enterprise controls by default, private-by-design data access.
TALK TO OUR EXPERTS
Why trust Taskmonk for e-commerce AI data projects
Proven at scale
Over 200M tasks and 5M+ annotation hours delivered across images, video frames, audio, text, PDFs, DICOM, and LiDAR/geospatial, supporting large, multi-team programs in healthcare, retail, autonomy, and enterprise AI.
Trusted by enterprises
More than eight Fortune 500 companies trust Taskmonk to run secure, accurate, and scalable multimodal labeling and human evaluation, meeting strict governance while accelerating production AI across regulated and data-intensive workloads.
Measurable outcomes
Clients have saved $4M+ through higher agreement, fewer rework loops, and automation that reduces clicks per label, shortening cycles from dataset to model while improving coverage on long-tail multimodal cases.
Reliable delivery
99.9% uptime on Azure and a network of 7,500+ vetted annotators keep multimodal programs on schedule, with elastic capacity and SLA tracking to ensure quality at scale without disruptions.
Proven at scale
Over 200M tasks and 5M+ annotation hours delivered across images, video frames, audio, text, PDFs, DICOM, and LiDAR/geospatial, supporting large, multi-team programs in healthcare, retail, autonomy, and enterprise AI.
Trusted by enterprises
More than eight Fortune 500 companies trust Taskmonk to run secure, accurate, and scalable multimodal labeling and human evaluation, meeting strict governance while accelerating production AI across regulated and data-intensive workloads.
Measurable outcomes
Clients have saved $4M+ through higher agreement, fewer rework loops, and automation that reduces clicks per label, shortening cycles from dataset to model while improving coverage on long-tail multimodal cases.
Reliable delivery
99.9% uptime on Azure and a network of 7,500+ vetted annotators keep multimodal programs on schedule, with elastic capacity and SLA tracking to ensure quality at scale without disruptions.
Multimodal data labeling and expert execution services with Taskmonk platform
Scale faster with a vetted workforce trained across images, video, audio, text, PDFs, LiDAR, and DICOM—operating on the Taskmonk platform with measurable QA and SLAs.
TALK TO OUR EXPERTS
End-to-end project management
We scope the task, codify guidelines, stand up workflows, staff annotators and reviewers, and run QA through delivery. One point of contact, weekly SLAs, and transparent in-platform dashboards.
Multimodal data annotation expertise
Teams experienced with image/video boxes and masks, keyframe tracking, audio ASR and diarization, OCR and layout for documents, LiDAR point clouds, and DICOM with reports—calibrated using gold tasks and challenge sets.
Secure, scalable, cost-predictable
Projects of any size delivered reliably with transparent pricing, enterprise-grade security, VPC or signed-URL access, region pinning, and predictable timelines your stakeholders can plan around.
Proof of concept
Share a sample dataset and SOPs plus goals. We’ll stand up a workflow, assign annotators, and return labeled samples with a QA snapshot within 24–48 hours.
End-to-end project management
We scope the task, codify guidelines, stand up workflows, staff annotators and reviewers, and run QA through delivery. One point of contact, weekly SLAs, and transparent in-platform dashboards.
Multimodal data annotation expertise
Teams experienced with image/video boxes and masks, keyframe tracking, audio ASR and diarization, OCR and layout for documents, LiDAR point clouds, and DICOM with reports—calibrated using gold tasks and challenge sets.
Secure, scalable, cost-predictable
Projects of any size delivered reliably with transparent pricing, enterprise-grade security, VPC or signed-URL access, region pinning, and predictable timelines your stakeholders can plan around.
Proof of concept
Share a sample dataset and SOPs plus goals. We’ll stand up a workflow, assign annotators, and return labeled samples with a QA snapshot within 24–48 hours.
FAQ
What export formats of multimodal data and integrations are available?
Export JSONL, COCO, YOLO, CSV, or custom schemas. Stream to training via APIs/webhooks/SDKs and write outputs directly to S3, GCS, or Azure.
How are annotators vetted and onboarded?
Screening, domain training, and calibration against gold tasks. We measure individual and team accuracy, enforce SLAs, and retrain on edge cases found in challenge sets.
How is pricing structured?
Platform is subscription-based. Services are priced per task or hour with clear SLAs. We provide an estimate after reviewing scope, volumes, and quality targets.
Share a small dataset and goals. We’ll configure a workflow, label a subset, and return a QA snapshot within 24–48 hours—on your storage