Introduction
Ask any ML team where the grind lives, and you’ll hear the same refrain: the work is in the data.
Data preparation—collecting, cleaning, structuring, and data labeling for training data preparation soaks up the lion’s share of effort for building AI Data Annotation models (Cognilytica research surveys show about 80%).
That 80% figure underlines how critical data annotation is for a well-functioning AI. That huge focus isn’t a waste; it’s leverage. With open-sourced architectures &LLMs available today, competitive edge now comes from the data quality, annotation consistency, and the velocity of your labeled-data pipeline, which determines how fast models improve.
This is the crux of the trade-off your organization feels every day:
Data engineers and scientists push for uncompromising label quality because it dictates downstream accuracy and reliability; project owners & Business heads need working AI models fast because roadmaps, pilots, and budgets don’t wait for anyone.
The best practice today is to treat data like an evolving product—one refined with every iteration. This is the core of data-centric AI: strengthening ontologies, tightening annotation workflows, and producing higher-quality ground truth that directly accelerates model improvement.
Here is a guide that covers data labeling 101.
Data labeling typically happens in one of two ways: fully manual, where humans provide expert judgment, or automated, where AI models and rules generate prelabels or preannotations that humans refine. Both approaches matter—but the real advantage comes from knowing when to use each.
Manual data annotation gives you granular control and edge-case fidelity, but it’s slow and costly at scale.
Automated data labeling accelerates throughput and shortens iteration loops, yet can propagate model bias or low-confidence errors without the right human checks.
In this blog, we cover manual vs automated data labeling, when to use each, and why hybrid(model-assisted labeling with human-in-the-loop annotation) tends to deliver the best balance of accuracy, speed, and Data Labeling cost for most production datasets.
Data Labeling Approaches: Manual and Automated Data Labeling
There are two primary ways to create training labels: manual (human-only) and automated (AI-driven or programmatic).
In practice, most teams adopt a hybrid approach: models prelabel routine items, while humans review and correct edge cases.
Below, we outline manual vs. automated; the next section dives into hybrid as the pragmatic default.
Manual data labeling
In manual data labeling, trained annotators apply labels using guidelines, examples, and calibration sessions.
This expert-led approach excels when you’re dealing with new domains, ambiguous classes, or safety-critical use cases where nuance matters more than speed.
However, the trade-off with manual labeling is cost and throughput: scaling requires larger teams, stricter QA, and more reviewer time to maintain consistency as ontologies evolve.

Pros of manual data labeling
- Edge-case fidelity: Human annotators resolve ambiguity, apply domain context, and navigate gray areas (like nested entities, partial occlusions, or sarcasm). This directly improves downstream precision and recall in long-tail class coverage.
- Auditability and compliance: Every decision is attributable. Rationales, reviewer IDs, and change logs can be preserved, which is critical for regulated domains and when explanations are needed for internal risk teams & compliance requirements.
- Rare-class recall: Annotators can spot infrequent or emerging classes that automation often misses. This strengthens coverage of the long tail and reduces the risk of surprise errors in production.
- Rapid policy adaptation: Annotators adjust immediately when guidelines or taxonomies change, enabling continuous delivery while the model retrains and catches up.
Cons of Manual Data Labeling
- Throughput & cost ceiling: Scaling purely with people increases unit cost and turnaround time. Large surges or tight SLAs are hard to sustain without substantial workforce expansion.
- Quality variance without calibration: Without calibration, annotation drift and inconsistent inter‑annotator agreement occur. You need gold sets, reviewer training, and adjudication to maintain tight consistency over time.
- Slower learning cycles: Label acquisition occurs at human speed, delaying retraining and increasing the interval between model iterations.
- Operational fragility under surges: Hiring, onboarding, and ramp-up of the right resources require time. Unexpected volume or new cases may cause delivery bottlenecks.
Automated data labeling
Automated labeling produces labels without human review, using artificial intelligence models for computer vision, natural language processing, or large language models (LLMs), as well as deterministic rules such as regular expressions (regex), manual heuristics, template matches, or weak-supervision label functions.
It’s unbeatable for speed and cost efficiency on stable, high-agreement tasks like barcode recognition, simple image bounding boxes, or structured text fields in optical character recognition (OCR).
On the other hand, automation can silently propagate errors, amplify bias, and miss drift or novel classes unless you maintain strong sampling audits or downstream validation.
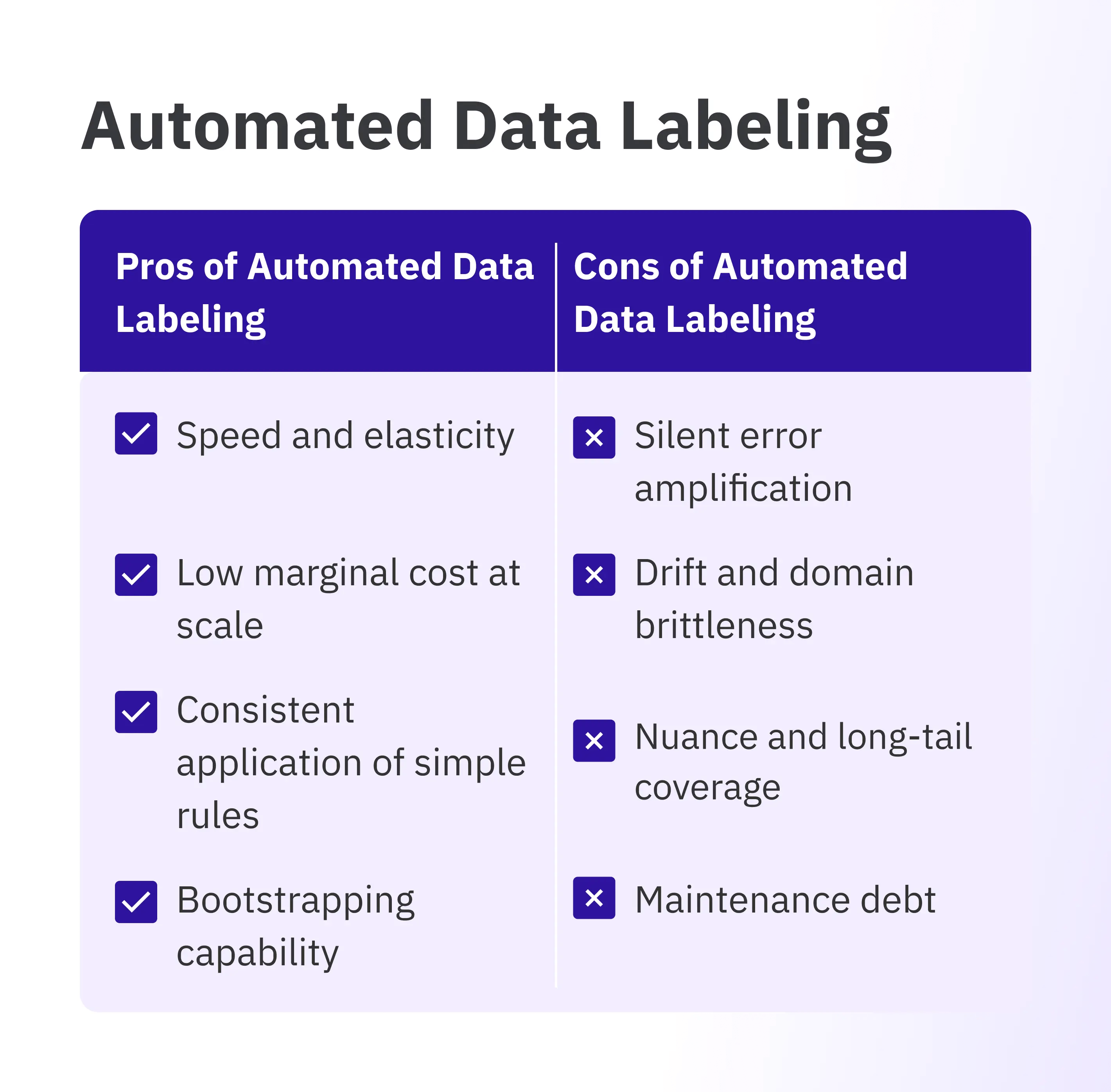
Pros of automated data labeling
- Speed and elasticity: Models and rules can pre-label huge batches in minutes, shrinking cycle times and smoothing spikes without recruiting overhead.
- Low marginal cost at scale: After pipeline setup, the cost per item remains low—ideal for extensive, repetitive workloads.
- Consistent application of simple rules: Deterministic logic and mature models deliver uniform labeling performance on high-agreement tasks (such as barcodes, simple boxes, or templated fields).
- Bootstrapping capability: Fast, weak prelabels enable annotators to prioritize hard cases, focusing human effort on complex items instead of starting from scratch.
Cons of automated data labeling
- Silent error amplification: Without ongoing sampling and auditing, systemic mistakes (bias, misclassification) can repeat throughout the dataset, and models learn incorrect patterns rapidly.
- Drift and domain brittleness: Performance drops when data shifts or new classes arrive; without continual monitoring, metric degradation may go unnoticed.
- Nuance and long-tail coverage: Automated approaches struggle with subtle semantics, rare classes, and multi-step reasoning. Apparent confidence may remain high even when predictions are incorrect.
- Maintenance debt: Rules and models require ongoing tuning; without ownership and monitoring, accuracy drops and automation grows stale.
Hybrid (Model-Assisted + HITL): How It Works and Why It’s the Default
Most teams discover that pure manual or pure automated pipelines break down at scale. Hybrid labeling bridges this gap by letting automation handle the routine while humans focus on nuanced, high-impact decisions.
Hybrid labeling starts with an automated first pass that proposes labels, then hands control to a human to accept, correct, or escalate.
Instead of annotators to label everything from scratch, you let automation clear the routine cases and reserve human attention for ambiguity, rare classes, and policy-sensitive judgments.
The workflow is simple in spirit: prelabel → route by confidence/complexity → review and adjudicate → feed corrections back into the next model update.
Routing is the engine that keeps quality high. Items with very high confidence and simple structure can be batch-approved with light auditing; borderline cases flow to reviewers; truly uncertain or policy-critical items go to an adjudicator queue.
This confidence-aware triage prevents “silent failure” (large volumes of wrong labels slipping through) while still delivering the cycle-time benefits of automation.
Quality assurance in the Hybrid labeling approach sits on two rails, building on the confidence-based routing above to prevent silent failure while keeping speed gains from automation:
- Structural checks — rule-based “must-pass” validations that block obvious mistakes before anything is counted as done.
Think schema completeness (required fields present, no illegal values), geometry validity for CV/Doc AI (boxes in bounds, polygons not self-intersecting), format/type guards (dates parse, IDs validate), and ontology consistency (only permitted labels, mutually exclusive tags enforced). If a check fails, the item is automatically rerouted for correction or escalation. - Statistical safeguards — sampling, thresholds, and monitors that catch systemic errors over time. Use confidence-band auditing (e.g., 5% for high-confidence, 20% mid, 100% low), class-level precision floors that pause auto-accept when a class slips, and rotating gold/IAA to keep humans calibrated.
Add drift detectors and control charts on reject/rework rates; when alarms trip, increase audits or disable automation for the affected slice until quality recovers.
A hybrid loop should get faster over time. Corrections, disagreements, and misses are highly informative examples; prioritize them for retraining or active learning, along with including uncertainty sampling, diversity sampling, and hard negative mining. So the next prelabel pass is stronger, and the human review fraction shrinks.
The net effect is a steady improvement in effective F1 score with decreasing human minutes per accepted item.
Accuracy comparison: pure manual vs. AI-assisted vs. hybrid by use case
Accuracy isn’t one-size-fits-all; it depends on data modality, ontology granularity, and how often the real world changes under your feet.
Below is a practical view of which approach tends to win for common workloads, and which metrics to anchor on so your comparisons are apples-to-apples.
Computer Vision
- Manual wins when: new camera domains, fine-grained attributes, or tiny/occluded objects in cluttered scenes dominate.
- Automated wins when: fixed rigs and repeatable patterns (e.g., barcodes, uniform SKUs, conveyor inspections) make labels near-deterministic.
- Hybrid usually best: production feeds with periodic lighting/packaging changes—models clear routine frames; reviewers handle edge occlusions and class drift.
Document AI
- Manual wins when: mixed bundles, unconventional layouts, or handwriting-heavy archives make structure unpredictable.
- Automated wins when: single-template forms with checksums/field constraints (e.g., meter bills) are the norm.
- Hybrid usually best: multi-vendor invoices and KYC packs—models extract fields/tables; reviewers resolve splits/merges and ambiguous values.
NLP
- Manual wins when: a new taxonomy, dense domain slang/abbreviations, or nested entities/relations make guidance fluid.
- Automated wins when: broad-domain topic tags, toxicity flags, or short intent labels have obvious cues at scale.
- Hybrid usually best: enterprise NER/RE with evolving product names—models mark spans/links; humans adjust boundaries and rare classes.
Speech & Audio
- Manual wins when: frequent code-switching, overlapping speakers, or noisy field recordings with uncommon terms are prevalent.
- Automated wins when: single-language IVR, studio-quality speech, or simple event pings are consistent and clean.
- Hybrid usually best: contact-center analytics across regions—models draft transcripts/diarization; reviewers fix accent clusters and timing drift.
How Taskmonk Employs Hybrid Labeling in Real-World AI Projects
Taskmonk treats hybrid data labeling as an operating model. Automated data labeling Platforms handles the repeatable labeling step, prelabels, validations, and routing while reviewers focus on judgment calls.
Every correction powers smarter next passes. As policies change, hard cases surface automatically and calibration stays targeted, so SLAs hold, quality improves, and rework drops.
Here is what a sample workflow looks like for an AI project:
Conclusion
For AI teams today, the real competitive advantage no longer comes from model architectures—it comes from the quality, consistency, and velocity of ground-truth data. Manual data labeling accuracy ensures nuance, and automated labeling ensures scale, but neither alone can keep pace with changing business requirements, evolving ontologies, or shifting real-world data.
Hybrid data annotation has emerged as the strategic default because it aligns with how high-performing ML organizations operate: automation handles repeatable work, humans resolve ambiguity, and every correction strengthens the model. This creates a self-improving labeling pipeline—one that reduces cost, accelerates iteration, and continuously lifts model performance.
For leaders responsible for production ML systems, the goal isn’t just cheaper labels; it’s predictable quality, measurable accuracy, and a labeling workflow that matures alongside the model lifecycle. Hybrid delivers all three, while pure manual or pure automation introduces bottlenecks—either in speed or in reliability.
Taskmonk makes this hybrid strategy operational. Its model-assisted labeling, confidence-based routing, and structured QA pipelines ensure that automation accelerates throughput while humans safeguard edge-case accuracy. Every correction feeds back into the system, so your labeling pipeline gets faster, cheaper, and more accurate over time—without sacrificing governance or auditability.
Ready to build a faster, more accurate labeling workflow?
Explore Taskmonk’s hybrid annotation platform and see how your team can ship better models in less time.
.png)

