.png)
The Ultimate Data Labeling Guide 2025
AI breakthroughs in 2025 are powered by one key factor: better data.
Whether you’re training autonomous driving systems, powering ecommerce search, or fine-tuning an LLM, your model is only as good as the data annotation behind it.
Enterprise AI teams now need multimodal, LLM-ready datasets that are accurate, compliant, and delivered on predictable timelines. That raises the bar for how data labeling gets planned, executed, and audited at scale.
More data isn’t better data—better data is. Bloated, low-quality corpora slow down the data annotation process, inflate review cycles, and push production dates.
AI teams have to focus more on high-quality data to implement better capabilities in their AI models. Curate for quality up front to avoid rework and high data labeling costs.
This guide explains what “enterprise-ready” data labeling looks like today. You’ll learn the core modalities to prioritize, how LLMs and AI agents change labeling requirements, and how sourcing models compare in real programs. If you’re comparing data labeling types or platforms or reworking your labeling operations, use this guide as a practical playbook: what to build, what to buy, where humans can add the most value, and how to meet compliance requirements. This list also contains best data labeling tools for 2026!
TL;DR: 2025 marks a shift from big data to better data. Multimodal Data Labeling Model AI, LLMs, and tighter compliance, a hybrid data labeling model (platform plus experts plus automation) provides enterprises speed, control, and production-grade quality.
Data Labeling Priorities in 2025 (What Enterprises Look For)
In 2025, everyone from boards to product teams is seeing how models are trained and why data labeling is the lever.
Big-ticket moves like Meta’s ~$14.3B investment for a 49% stake in Scale AI put training data and labeling infrastructure squarely in the spotlight, signaling that high-quality, governed labeled data is now a strategic asset for enterprise AI.
- From volume to value: Teams are shifting from labeling everything to curating high-signal examples at the right volume. Tighter taxonomies and clearer guidelines reduce corrections and lift model performance.
- Multimodal is mainstream: Vision, text, audio, geospatial, and sensor streams now flow through one workflow. A single platform must handle bounding boxes, transcripts, LiDAR, and medical data annotation without fragile handoffs.
- LLMs and agents require context: Instruction and safety labels, retrieval-ready metadata, and domain nuance demand human judgment on ambiguous cases.
- Compliance becomes mandatory: GDPR, HIPAA, and DPDP Act require privacy by design: PII(Personally Identifiable Information) and PHI(Protected Health Information) handling, consent tracking, RBAC, audit trails, and region-aware storage.
- AI assist, human in charge: Pre-labeling, model triage, and active learning by AI models increase throughput. Humans still arbitrate ambiguity and enforce quality bars.
- Quality is measured: Multi-layer QC, gold sets, reviewer calibration, and error taxonomies are tracked like model metrics.
- Speed with control: Business needs reliable SLAs and cost visibility. Engineering needs APIs and orchestration. Security needs VPC, SSO, and data residency. The modern stack serves all three.
- Outcome over output: Success is production impact: precision and recall, cost to serve, fraud reduction, and SLA adherence, not hours logged.
What Is Data Labeling in AI
Data labeling is the process of attaching meaningful tags, structures, or labels to raw data (such as text, images, video, audio, etc.) so that machine learning models can learn the correct patterns.
In practice, that means converting text, images, video, audio, and sensor streams into labeled data that reflects your business rules for thousands and millions of items.
Here is a simple analogy-Think of training as a flight simulator. If the simulator’s scenes are mislabeled or missing, pilots learn the wrong moves.
AI Models behave the same way. Weak or inconsistent data annotation teaches the wrong behavior and shows up later as poor precision, brittle edge-case handling, and unpredictable failures in production.
Why data labeling makes or breaks AI.
- AI Models learn what you label: If the label schema is vague or the taxonomy drifts, the model optimizes against noise instead of signal.
- Errors compound: A small percentage of incorrect labels early on can cascade through active learning and retraining, inflating rework and slowing releases.
- Compliance is downstream of labeling: Privacy flags, PHI/PII data anonymization, and consent metadata must be captured at the labeling stage to satisfy audits later.
- Modality depth matters: Computer vision, NLP, speech, and geospatial data each need modality-specific guidelines, tools, and quality assurance to reach production-grade reliability.
What does good data labeling look like?
- A clear ontology and examples that cover common cases and edge cases.
- Reviewer workflows with double-blind checks, gold tasks, and calibrated scoring.
- Measurable quality gates tied to model metrics, not just throughput.
- A data labeling platform or labeling platform that supports multimodal workflows, versioned guidelines, audit trails, and role-based access.
- A culture of “high quality data first,” where annotators understand business impact and can flag ambiguous inputs.
Get these foundations right and everything upstream and downstream runs smoother: faster iteration, lower labeling costs, fewer surprises during integration, and models that generalize better in the real world.
What Are the Main Types of Data Labeling?
Enterprises rarely work with a single data format anymore. Each modality has its own tasks, tools, and quality assurance checks.
Different data types are utilized in different fields of AI, like NLP annotation powers LLMs and retrieval; computer vision relies on image and video labels; speech uses timestamped transcripts and diarization; geospatial needs precise geometry and 3D alignment.
A unified data labeling platform keeps ontologies and reviews consistent so you ship high quality data to training.
Text and NLP Annotation
Text annotation turns unstructured language into structured, labeled data that models can search, reason over, and act on. It supports assistants, RAG pipelines, document automation, compliance workflows, and post-training of LLMs.
In enterprise settings, the focus of text data annotation is on consistent schemas, privacy-aware processing, and measurable quality assurance so the output becomes high-quality data for production training and evaluation.
Generally used for: chatbots and search, contract and EMR parsing, knowledge extraction, RAG metadata, safety & policy enforcement.

Primary tasks:
- Intent classification for routing, for example, mapping a user query to billing, support, or sales.
- Topic or taxonomy classification, for example, assigning documents to product, risk, or department categories.
- Named entity recognition (NER), for example, tagging PII, PHI, IDs, ICD codes, drug names, and SKU attributes.
- Relation extraction, for example, linking drug → dosage, account → transaction, product → attribute.
- Coreference and entity resolution, for example, resolving “he,” “the patient,” or duplicate customer records.
- Span-level QA and extraction, for example, the exact answers with evidence highlights for evaluation and RAG.
- Instruction, preference, and safety datasets for LLMs, for example, prompt response pairs, pairwise rankings, red teaming, and policy labeling.
QA and metrics:
- Inter-annotator agreement per label (Cohen’s κ or Krippendorff’s α) with go or no-go thresholds.
- Benchmark and gold tasks seeded in queues; Exact Match and F1 for spans; precision/recall for entities and relations.
- Calibration reviews with confusion matrices, error taxonomies, and drift checks over time.
- Privacy audits that verify redaction coverage, access controls, and complete audit trails linking back to the data labeling platform.
Ops tips:
Maintain a versioned ontology with canonical examples, use programmatic pre-labeling and validators, and push outputs through your data labeling platform API so data annotation stays consistent across teams.
Image Labeling
Image annotation powers computer vision in e-commerce, healthcare, manufacturing, and ADAS. Labels range from attributes to dense masks and landmarks that drive perception, inspection, and retrieval.
Generally used for: product attribute tagging and quality checks, medical imaging review, defect detection, and road scene understanding.
Primary tasks:
- Attribute and class assignment, e.g., product color, material, or condition.
- Object detection with bounding boxes, e.g., vehicles, tumors, defects.
- Instance and semantic segmentation with polygons or masks, e.g., drivable area, organ boundaries, surface defects.
- Keypoints and landmarks, e.g., facial landmarks, skeletal pose, measurement anchors.
- Pairwise similarity and duplicate detection, e.g., near-duplicate SKUs, visual search indexing.

QA and metrics:
- IoU targets per class and mAP/mAR for detection quality.
- Dice or pixel accuracy for segmentation, plus boundary accuracy on thin or complex shapes.
- Consensus and reviewer agreement, with bias checks for hard classes.
- Golden sets and version diffs to catch silent regressions across releases.
Ops tips:
templatize attributes per category, enable model-assisted pre-labels, and prioritize uncertain images with active learning so effort lands where it lifts accuracy most.
Video Labeling
Video labeling involves marking not just what is in a single frame, you are following the same object across seconds or minutes, through occlusions, camera motion, lighting changes, and crowded scenes. Video introduces time and identity during annotation.
Good setups define clip lengths, overlap between clips, and what counts as an event or state change. In multi-sensor programs, you also align video with LiDAR, radar, or telemetry so labels stay consistent across sources.
Generally used for: ADAS scene understanding, surveillance and incident review, retail analytics, and sports analysis.
Primary tasks:
- Multi-object tracking with identity persistence, including occlusions and re-entry.
- Temporal segmentation of shots, activities, and states.
- Action and event detection, e.g., lane change, fall detection, theft, handover.
- Frame-level attributes tied to tracks, e.g., hazard flags, behavior states.
QA and metrics:
- Multi-object tracking with identity persistence, keeping each object’s ID stable as it moves, disappears, and reappears.
- Temporal segmentation, marking scene boundaries, phases, or activity windows.
- Action and event detection, such as lane changes, falls, handovers, rule violations, or hazards.
- Frame-level attributes tied to tracks, for example turn signals, head pose, or equipment status.
- Cross-camera re-identification when the same object appears across views or sensors.
Ops tips:
fix clip lengths and sampling policy early, use proposals or optical flow to draft tracks, and escalate low-confidence segments to senior reviewers rather than redrawing from scratch.
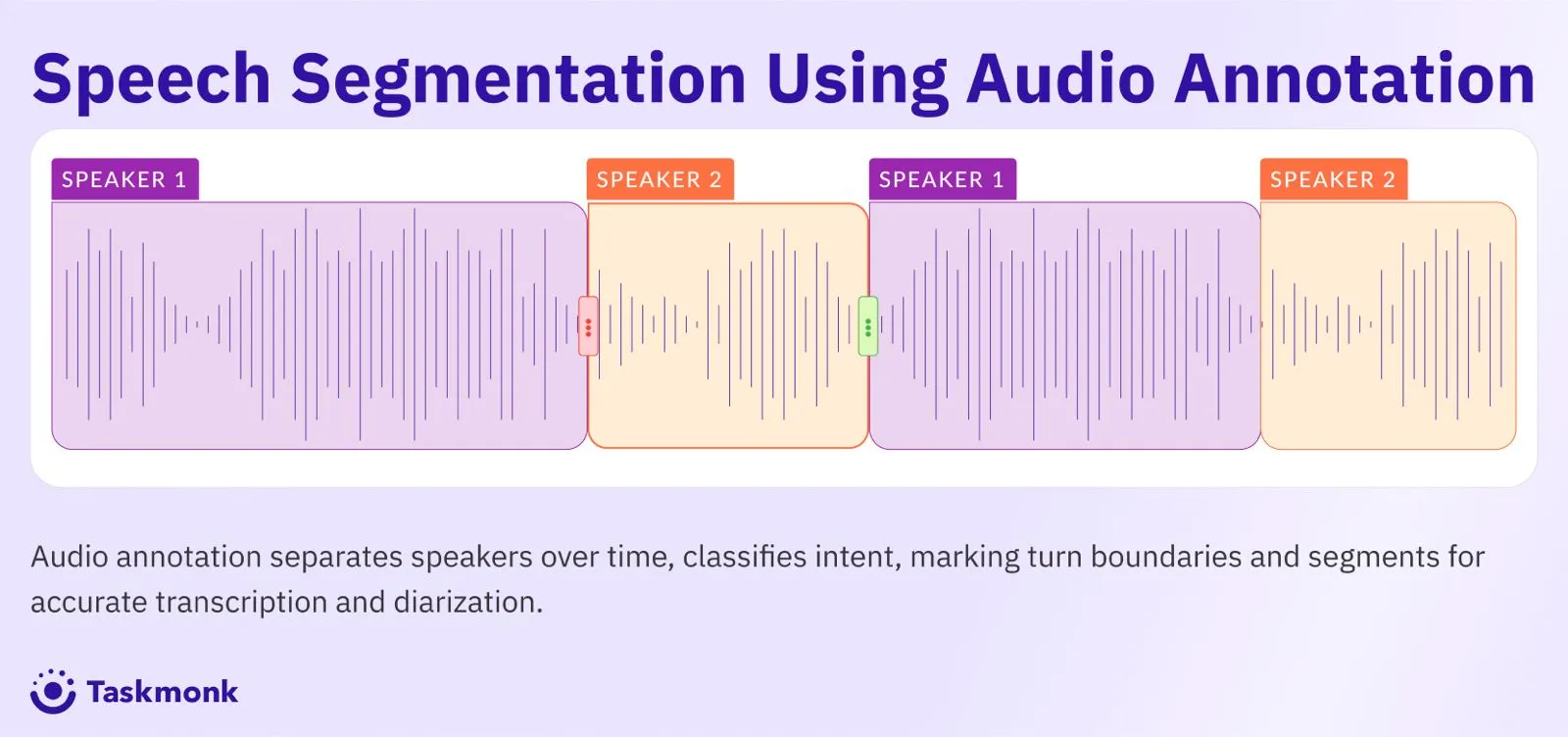
Audio and Speech Annotation
Audio annotation converts speech and sound into structured, labeled data that models can transcribe, understand, and act on. It must account for accents, background noise, overlapping speakers, and privacy.
Success depends on accurate timestamps, clear speaker boundaries, and policies for redacting sensitive information so the result is high quality data you can use in production.
Generally used for: ASR and multilingual voice assistants, contact-center analytics, and compliance monitoring, BFSI fraud detection from call audio, voice biometrics evaluation, etc
Primary tasks:
- Timestamped transcription with punctuation and casing standards.
- Speaker diarization with turn boundaries and overlap handling.
- Intent and slot labeling for task routing and fulfillment.
- Keyword spotting and wake-word validation with false accept and reject review.
- Sentiment or emotion tagging, where policy permits.
- PII and PCI anonymization for names, card numbers, and other sensitive fields.
QA and metrics:
- WER and CER for transcription accuracy; DER for diarization.
- Alignment tolerance at word or phoneme level for time-critical use cases.
- Redaction precision and recall to validate privacy compliance.
- Accent and noise coverage matrix to confirm reviewer capability across conditions.
Ops tips:
provide domain lexicons and pronunciation dictionaries, capture multi-channel audio to separate speakers, and standardize style guides to stabilize downstream training.
Geospatial and Sensor Data
Geospatial and sensor labeling supports autonomy, mapping, and logistics. It blends imagery with signals like LiDAR, radar, GPS, and IMU. Precision and consistency are critical because small geometric errors can cascade into routing mistakes or unsafe behavior.
Generally used for: satellite and aerial mapping, last-mile routing and curb detection, asset and vegetation monitoring, drone inspection, warehouse and yard automation, ADAS sensor fusion.

Primary tasks:
- Vector mapping with polygons and lines, e.g., buildings, roads, curbs, lanes.
- 3D labeling with bounding boxes or semantic segmentation on LiDAR and radar point clouds.
- Change detection across dates for construction, damage, vegetation growth, or flood impact.
- Sensor-fusion alignment that synchronizes camera frames with LiDAR, radar, GPS, and IMU so objects match across sources.
QA and metrics:
- Positional accuracy using RMSE or CEP; CRS validation and reprojection checks.
- Per-class IoU for polygons and point-level accuracy for 3D.
- Topology validators for gaps, overlaps, and self-intersections.
- Cross-sensor consistency audits before model ingestion.
Ops tips:
tile large areas into manageable sectors, run automated geometry validators first, then route exceptions to human review to keep throughput high.
Data Labeling for LLMs and AI Agents
LLMs and agents do not just need more data, they need high quality data with clear intent, policy context, and evidence. The challenge isn’t labeling a few thousand prompts—it’s orchestrating large-scale labeling workflows across millions of transactions, catalog items, or records, while still passing compliance review and meeting regional regulations.
That requires data labeling workflows designed for instructions, preferences, safety, and grounding.
The goal is to turn raw logs and documents into labeled data that reliably improves helpfulness, reduces hallucination, and passes compliance review.
Generally used for:
BFSI fraud and risk triage agents, healthcare assistants that summarize EMRs and imaging notes, ecommerce copilots that answer product questions and guide checkout, enterprise copilots that search policies and draft responses.
Primary tasks :
- Supervised fine-tuning (SFT): curate prompt–response pairs that represent your brand voice, domain rules, and acceptable depth of answer.
- Preference and ranking data: pairwise comparisons or scalar scores using a rubric, so models prefer on-policy responses over plausible but risky ones
- Safety and policy labeling: tag disallowed content, sensitive topics, and escalation paths, then map to policy sections for auditability.
- Grounded QA and citation checks: label answer spans and required sources, verify that claims are supported, and flag missing citations.
- Tool and function-use annotations: specify when the agent should call a function, what arguments to pass, and how to merge tool output into replies.
- Dialogue state and handoff: mark customer intent, state changes, and when to hand off to a human or specialized system.
- Data hygiene: PII/PHI redaction, de-duplication, and leakage checks against test sets and restricted corpora.
Quality assurance and metrics:
- Rubric calibration: reviewers share examples of “good, borderline, bad” for each criterion before production; measure agreement on the rubric.
- Win rate and relevance: side-by-side comparisons against baselines on real tasks; track retrieval success and answer usefulness.
- Groundedness and factuality: exact-match or span-F1 on required evidence, citation correctness, and unsupported-claim rate.
- Safety adherence: policy-violation rate, proper refusal behavior, and correct escalation on protected topics.
- Coverage and bias: scenario matrix across intents, channels, languages, and user profiles, with minimum counts per cell.
- Privacy and audit: redaction precision/recall, access logs, and full provenance in the data labeling platform.
Human-in-the-loop with AI assist:
- Use AI-assisted pre-labeling to draft responses, reasons, or citations, then route low-confidence items to senior reviewers.
- Apply active learning to surface uncertain prompts and ambiguous policies first, which reduces rework and labeling cost.
- Version everything: guidelines, rubrics, prompts, and outputs, so data annotation is reproducible and tied to model releases.
Ops tips:
- Keep a living policy book inside the labeling platform, linked to examples and refusal templates.
- Maintain a small, frozen eval set that mirrors production; do not contaminate it with training edits.
- Store prompts, tool calls, citations, and reviewer decisions as structured metadata for fast audit and rollbacks.
What Makes a Great Enterprise Labeling Platform
Enterprises need a data labeling platform that delivers predictable throughput, measurable quality assurance, and airtight compliance across text, computer vision, audio, video, and geospatial projects.
The right labeling platform behaves like part of your MLOps stack: it version-controls work, automates the boring parts, and produces reproducible, high quality data that flows straight into training.
- Multimodal, one ontology: Support text, images, video, audio, LiDAR and radar in a single workspace. Reuse taxonomies and validation rules so different teams create compatible labeled data.
- Workflow orchestration: Queues for annotators, reviewers, and auditors with configurable stages: blind review, consensus, spot checks, and gold tasks. Capacity planning and SLAs visible to program owners.
- Quality assurance, built in: Metrics by modality (Exact Match and F1 for spans, IoU for masks, WER for transcripts, identity consistency for tracking). Dashboards tie label quality to downstream model KPIs so you fix what moves accuracy.
- AI assist, human control: Pre-labeling, auto-redaction, and programmatic validators reduce manual work. Active learning surfaces uncertain items first. Low-confidence labels route to senior reviewers.
- Security and compliance: SSO/SAML, RBAC, private networking or VPC peering, encryption at rest and in transit, data residency controls, retention windows, and complete audit logs. Mappings for GDPR, HIPAA, and India’s DPDP Act should be native, not bolted on.
- Versioning and lineage: Every change to guidelines, ontologies, and datasets is tracked. Snapshots and export manifests let you recreate a training run exactly.
- APIs and integrations: SDKs, webhooks, and connectors to S3, GCS, Azure, plus easy links into your MLOps tools. Batches should sync both ways with status, metrics, and provenance.
- Scalability and performance: Stable latency for large projects, support for thousands of concurrent sessions, and cost controls you can forecast.
Evaluator’s checklist
- Can we run text, image, video, audio, and geospatial in one project with a shared taxonomy?
- Do we get per-modality quality metrics and reviewer analytics out of the box?
- Are privacy controls, audit trails, and data residency configurable per project?
- Can we version guidelines and export exact dataset snapshots for audit and rollback?
- Do APIs support automated pre-labeling, active learning, and seamless retraining?
Proof to request in a PoC
- A production-like work with gold tasks and a target quality bar.
- End-to-end export: dataset snapshot, guideline version, and audit log.
- Demonstration of a quality issue found in the platform and the model lift after fixing it [in most projects].
- Security and compliance validation inside the data labeling platform
What Are the Different Data Labeling Sourcing Models
How you source data labeling work determines cost, speed, risk, and the level of control you keep. Most enterprises do not pick a single path. They combine models and coordinate them through a central data labeling platform so guidelines, quality assurance, and audit trails stay consistent while volume scales.
Different data labeling sourcing models:
.webp)
Platform vs Service vs Hybrid: Choosing the Right Model
A good decision here sets the pace for everything that follows. Platform-only gives flexibility, service-only gives immediate capacity, and a hybrid model balances control with speed while keeping quality assurance measurable.
Platform-only
What it is: Your team runs work inside a data labeling platform. You own guidelines, reviewers, and delivery.
When it works: You have internal capacity, sensitive data, or fast-changing ontologies. Typical in regulated text/NLP, computer vision on proprietary images, or when labels review must happen daily.
Strengths: Full control, tight feedback loops, direct link between labeled data quality and model KPIs, easy automation and active learning.
Trade-offs: Requires staffing and operations maturity. Throughput can lag.
Proof points to check:
- Role-based access, audit trails, and region-aware storage
- SDKs and webhooks to pipe batches into training
- Reviewer analytics, benchmark sets, and re-runable exports
- Cost and time per task at your target volume
Service-only
What it is: A vendor supplies people, process, and often tools. You hand off tasks with a spec and receive high quality data back.
When it works: Clear, stable tasks and the need to scale quickly. Good for large image attributes, document classification at volume, or long-running backlogs.
Strengths: Predictable capacity, managed delivery, lower coordination overhead.
Trade-offs: Less control, slower iteration on guidelines, potential tool lock-in if work runs outside your labeling platform.
Proof points to check:
- SLAs tied to objective quality metrics, not just throughput
- Double-blind review and benchmark performance before launch
- Secure handling for PII/PHI with verifiable audits
- Ability to export complete provenance into your platform
Hybrid (Platform + Services + Automation)
What it is: A coordinated setup where a central data labeling platform routes the right task to the right workforce with AI assist, shared guidelines, and one audit trail.
When it works: For most enterprise programs, especially multimodal. For example, ADAS video and LiDAR need domain-trained reviewers while image attributes can run at crowd scale.
Strengths: Control where it matters, elasticity where you need it, and one source of truth for data labeling quality.
Trade-offs: Requires robust workflow orchestration and clear governance.
How it runs in practice:
- Use model-assisted pre-labeling to draft outputs.
- Send low-risk items to elastic capacity.
- Route judgment-heavy or confidential work to in-house or specialist teams.
- Enforce one ontology, guideline version, and quality assurance gate across every source.
- Push approved batches to training via a single API and export manifest.
Enterprise Best Practices for High-Quality Data Labeling
Keep it to the moves that shift model quality and delivery speed.
- Lock the ontology and examples first: Write unambiguous label names, edge cases, and exclusion rules. Include 5–10 canonical positives and hard negatives per class. For computer vision, add pixel-accurate examples with target IoU.
- Pilot on a benchmark set before scaling: Run a mixed-difficulty batch to validate throughput, reviewer agreement, and metric targets. Freeze this set to track progress release over release.
- Set task-level quality targets and review gates: Match metrics to task- Exact Match and F1 for spans, precision and recall for entities, IoU for masks, tracking continuity for video, WER for transcripts. Use blind review, consensus, and gold tasks.
- Use AI assist, keep humans for edge cases: Pre-label easy items and route low-confidence cases to senior reviewers. Document decisions so guidelines improve and labeled data stays consistent.
- Sample with intent: Adopt active learning and stratified sampling to focus on confusing inputs, long tails, and business-critical classes. This reduces rework and labeling cost.
- Automate the obvious, validate privacy in-line: Add schema checks, regex, geometry tests, and PII/PHI anonymization in the data labeling platform. Human time should go to judgment, not cleanup.
- Version and trace everything: Version guidelines, ontologies, and exports. Every batch of data labeling outputs should have a snapshot and manifest so training is reproducible and audits are simple.
How Taskmonk Helps Enterprises Label Smarter
Taskmonk is built for hybrid delivery: a data labeling platform plus expert annotation services and automation. You get multimodal workflows for text, computer vision, audio, video, and geospatial, with one ontology, one audit trail, and measurable quality assurance from day one.
The result is high quality labeled data that ship to training without drama.
Hybrid advantage, operationalized:
- Route each task to the right workforce. Use AI-assisted pre-labels for speed and keep human in the loop for edge cases and policy-sensitive items.
- Keep guidelines, rubrics, and versions inside the labeling platform, so updates flow to every queue at once.
- Track acceptance, rework, and reviewer agreement against downstream model KPIs, not just throughput.
Platform capabilities:
- Multimodal editors: boxes, masks, landmarks, tracks, transcripts, entities, relations, 3D, and vectors.
- Built-in quality assurance: Exact Match and F1 for spans, IoU for masks, timing accuracy for audio, identity continuity for video, and geometry checks for maps.
- Enterprise controls: SSO, RBAC, VPC or private cloud, region-aware storage for India and the US, full provenance.
- APIs and webhooks: That push approved data annotation outputs directly into training, evaluation, and monitoring pipelines.
Expert services when you need them:
- Domain-trained annotators and reviewers for e-commerce, healthcare, BFSI, ADAS, and geospatial.
- Playbooks for calibration, gold sets, and benchmark-driven signoff.
- Elastic capacity with SLAs, so spikes in volume do not stall releases.
What a typical pilot proves:
- A curated benchmark set labeled to target quality.
- An exportable dataset snapshot with guideline version, review logs, and acceptance metrics.
- A before and after model comparison that shows lift from cleaner labels and fewer edge-case misses.
See why enterprises choose Taskmonk’s hybrid model to scale data labeling with control, speed, and production-grade quality.
What Are the Future Trends in Data Labeling Beyond 2025?
- AI in the loop becomes default: AI-assisted pre-labels, auto-redaction, and triage inside the data labeling platform, with humans resolving ambiguity to protect high quality data.
- Portfolio-level active learning: sampling is planned across programs, focusing spend on uncertainty and long-tail classes that lift KPIs fastest.
- Policy-aware schemas: privacy and safety rules live in the label schema, so quality assurance includes redaction checks and consent metadata by design.
- Multimodal growth in 3D: routine fusion of video, computer vision, LiDAR, radar, and telemetry, with native tools for 3D editing and review.
- Versioned evaluation sets inside the labeling platform: A fixed, never-train-on suite with attached guideline and ontology versions. Every release must pass on this set so improvements are measurable, reproducible, and audit-ready.
Conclusion: Data Labeling Is the Hidden Power Move in Enterprise AI
Winning AI programs do not start with models. They start with data labeling that produces consistent and high quality data.
The right data labeling platform is the multiplier that that makes quality assurance, privacy, and lineage routine rather than heroic—managing versioned ontologies and guidelines, enforcing quality gates, and protecting privacy with access controls & data residency.
Data labeling is where you decide what the model should learn, how it will be judged, and what is safe to ship. A clear schema turns strategy into measurable targets, curated batches lift accuracy faster than dumping more data, and built-in compliance converts experiments into auditable releases with reproducible labeled data.
Modern AI model training is iterative. Curate a targeted batch, label it with clear guidelines, train, measure where the model fails, then feed those errors back into the next batch. The platform coordinates this loop so quality rises and time to production falls.
If you treat data annotation as a product function rather than a side task, lift in precision, recall, and cost to serve follows.
Ready to prove it on your stack? Run a PoC with Taskmonk that demonstrates quality, throughput, and model lift, plus a complete export for audit and reproducibility.
FAQs
- How do we estimate budget for enterprise data labeling without guesswork?
Map each labeling task to time per item, target quality, and reviewer tiers. Use your data labeling platform metrics (acceptance rate, rework, throughput) to model cost per accepted label. For computer vision, include class balance and segmentation complexity. This produces predictable spend for high quality data. - What does a clean handoff from data labeling to MLOps look like?
Export only approved labeled data with a manifest: dataset ID, ontology version, QC scores, reviewer tiers, and checksums. Training jobs watch a single bucket or API from the labeling platform, which guarantees lineage for audits and rollback. - How do we prevent evaluation leakage when we use real logs for data annotation?
Freeze an evaluation set before labeling begins, store it in the platform with a “no-train” tag, and block it in sampling rules. Add automated checks that reject any export where eval items appear in train or validation, which protects quality assurance and reported lift. - Can we use crowdsourcing and still meet GDPR, HIPAA, or DPDP requirements?
Yes, if the data labeling platform enforces RBAC, data residency, and on-platform work only. Redact PII or PHI at source, restrict downloads, and log reviewer activity. Keep regulated items in in-house or KPO queues, and route low-risk tasks to crowd. - How do we migrate from a legacy annotation tool to a modern platform without downtime?
Run a staggered cutover: export old projects with schema maps, import into the new data labeling platform, and run a short PoC on a benchmark set to validate parity. Lock ontology versions, compare QC metrics, then switch traffic by queue, not all at once.


