TL;DR
Your AI can’t fix messy catalogs without clean and accurate product labels. The right e-commerce annotation tool helps you turn product images and metadata into reliable training data for search relevance, recommendations, and catalog automation.
E-commerce annotation companies covered in this blog:
- Taskmonk
- SuperAnnotate
- V7
- Labelbox
- Encord
This guide is for enterprise e-commerce and marketplace teams where catalog quality directly impacts revenue and ops.
- You manage large, fast-changing catalogs (tens of thousands to millions of SKUs) across multiple sellers, brands, or regions
- Search relevance, filters, or recommendations are underperforming and affecting conversion, AOV, or return rates
- Seller-submitted data is inconsistent across categories, seasons, or geographies, creating a downstream QA burden
- You need predictable annotation throughput with SLAs—not one-off pilots or ad-hoc labeling projects
- Internal teams require measurable QA signals (accuracy, rework rate, turnaround time) to report progress to leadership
- You’re evaluating outsourced vs in-house annotation and need a defensible vendor shortlist for procurement, data, and product stakeholders
Introduction
In November 2025 alone, Semrush estimated roughly 240.32M monthly visits to Amazon, 149.09M to Flipkart, and 54.88M to Myntra.
Data shows ~30% of e-commerce visitors use internal site search, which implies these three platforms alone likely see ~4–5 million search-led shopping sessions every day.
The catch: search intent is precise, but product data isn’t always uniform at scale.
A shade might be tagged “navy” in one listing and “dark blue” in another. One item is placed under “Trousers,” a near-identical one under “Chinos.”
These gaps affect the relevance of search results. Baymard’s research reflects this—41% of sites don’t fully support common e-commerce query types, and nearly 50% make it hard to recover from zero-results searches, which often end in abandonment.
This is exactly where ecommerce data annotation earns its ROI: it creates the consistent labels (categories, attributes, visual tags, and QC rules) that make search, discovery, and catalog automation behave predictably.
E-commerce data annotation companies and their tool offerings make labeling of products possible. We will discuss the best companies offering in this blog.
How we curated this list
- Focused on e-commerce and retail-relevant annotation, not generic labeling
- Evaluated catalog workflows: taxonomy mapping, attribute normalization, listing QA
- Considered delivery models (managed services vs self-serve platforms)
- Assessed QA rigor: review loops, golden tasks, drift prevention
- Looked at scale readiness for continuous SKU inflow
- Reviewed positioning and customer feedback where publicly available (e.g., G2)
- Prioritized fit by use case, not “best overall” claims
Why do you need Data Annotation for your E-commerce business or Marketplace?
E-commerce data annotation turns your catalog into machine-readable training data. Without it, computer vision and NLP models train on noisy data, leading to inconsistent search query results, poor recommendations, and inconsistent catalog automation.
Here is what the right e-commerce data annotation & training data can unlock for online retailers and marketplaces.
When done well, e-commerce data annotation offers several business benefits and enables retail AI tobehave predictably in production.
Consistent labels across product images, listing text, and attributes enable you to improve search relevance, strengthen recommendations, and automate catalog enrichment without compromising quality as the assortment grows.
With a fair understanding of the need for data annotation for marketplaces and e-commerce businesses, let’s get on to the list of companies that are best for e-commerce data annotation.
Best E-commerce Annotation Companies in 2026
-
Taskmonk
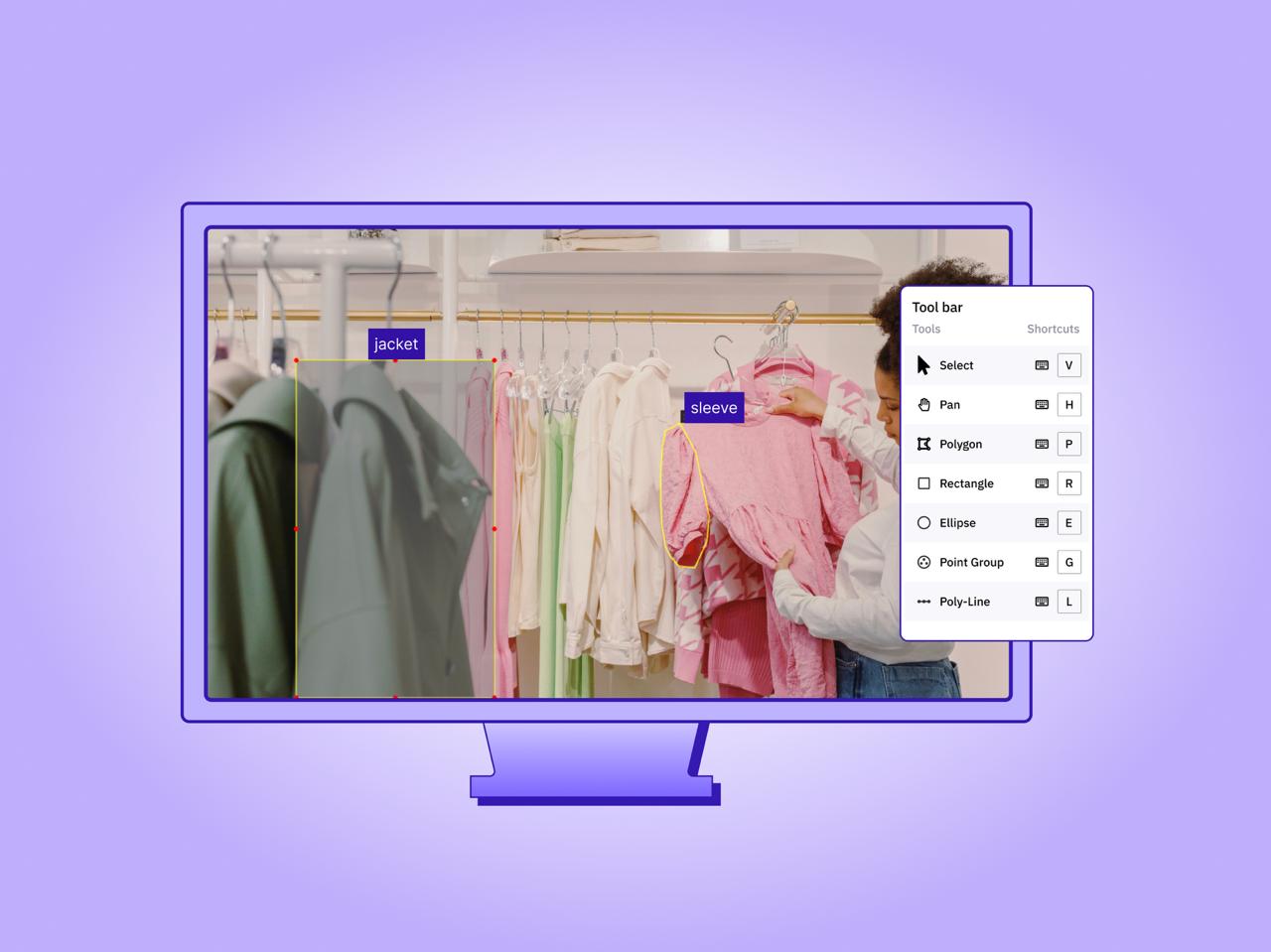
Taskmonk offers a F500 trusted data annotation platform and managed delivery model for e-commerce data annotation. It is built for catalog operations such as product categorization, catalog enrichment, and attribute tagging that remain consistent across sellers and seasons.
It supports product and UGC image labeling, including boxes and polygons. It also handles listing text workflows such as spec extraction, title normalization, and review/Q&A signals. Teams can build export-ready datasets for search, filters, and recommendations.
Quality is baked into delivery through review paths, sampling, golden tasks, and validation checks.
G2 reviewers across ecommerce frequently call out ease of use, quick setup, and quality control that doesn’t slow workflows, plus a stellar & responsive support.
Taskmonk has a strong depth in retail and marketplace workflows. It supports large-scale programs for global brands like Walmart, Flipkart, and Myntra. That experience shows up in playbooks for category-wise attributes, edge-case handling, and reviewer calibration.
Why Taskmonk stands out for e-commerce annotation
- Catalog-first workflows: Designed for taxonomy mapping (organizing product types), attribute normalization (standardizing product details), and catalog enrichment (adding comprehensive details) rather than just providing generic labeling.
- Image + text labels, in one workflow: Label product visuals and listing text together to train models for search relevance, clean filters, and similar-item recommendations, without stitching datasets from multiple tools.
- QA prevents label drift: Multi-step reviews, golden tasks, sampling, and validation rules ensure consistent output across categories and teams
- Operational visibility: Track throughput, rework rate, and QA pass % by category, so catalog teams can run weekly sprints without guesswork.
- Category-trained reviewers + calibrated QA: For high-risk categories and ambiguous attributes, Taskmonk uses category-trained reviewers, QA techniques, and periodic calibration audits to keep labeling decisions consistent across sellers, seasons, and catalog expansion.
- Scale-ready delivery: Built for continuous annotation backlogs, not one-off pilots.
Best for
Large-scale marketplaces and retailers running ongoing catalog programs: categorization, attribute tagging, product image labeling, and listing QA at scale.
Not ideal for
Teams that only need a lightweight labeling UI for occasional experiments and don’t want structured QA/process. -
SuperAnnotate
SuperAnnotate is a data annotation platform built for teams that want tight control over dataset creation, review workflows, and QA at scale. The reviewers point out ease of use and annotation efficiency.
For e-commerce teams, it’s typically best when you already have clear labeling guidelines and want a system to execute them while keeping day-to-day catalog ops (like attribute normalization and taxonomy mapping) handled by your internal team or a separate services partner.
SuperAnnotate is powerful, but teams with very specific workflows find customization limits in certain areas, and new users often need a ramp-up period before they can move fast.
Why SuperAnnotate stands out
- QA automation + structured review: Designed for multi-step review flows and catching label errors early, which helps reduce rework.
- Dataset management: Good for organizing projects, iterating on schemas, and managing dataset versions as models evolve.
- Enterprise readiness: Built with larger teams in mind—collaboration, governance, and process controls are a core part of the product.
Best for
ML/data teams that want a platform for controlled annotation programs (especially CV-heavy use cases). Organizations that already have annotators and want better tooling + QA discipline.
Not ideal for
Teams looking for an e-commerce-first, managed delivery approach (catalog enrichment, taxonomy, attribute tagging at weekly throughput). -
V7
V7 Darwin is a fast, AI-assisted labeling platform known for strong annotation UX and automation for segmentation-heavy work and teams that want to move quickly with model-assisted labeling.
For e-commerce, V7 can be useful for image-heavy initiatives (visual search, similar products, fashion segmentation), but many catalog programs still need additional layers like attribute consistency, taxonomy decisions, and large-scale operational QA.
V7 is great for fast CV labeling, but if your core need is ongoing catalog enrichment (taxonomy + attributes across SKUs), you may still need extra process layers outside the tool to keep outputs consistent.

Why V7 stands out
- AI-assisted annotation speed: Auto-annotation accelerators can reduce manual labeling effort, especially for segmentation tasks.
- Quality validation tooling: Strong emphasis on review and consistency checks to prevent sloppy datasets.
- Video + tracking capabilities: Helpful if you’re labeling short-form commerce video or walkthrough content.'
Best for
Image-heavy e-commerce initiatives, such as fashion segmentation or visual similarity. Companies with an internal labeling function that want faster tooling and automation.
Not ideal for
Large-scale catalog enrichment where consistency across attributes and categories is the main challenge. -
Labelbox
Labelbox is a widely adopted data labeling platform that combines annotation tooling with model-assisted labeling and configurable workflows.
It is flexible and feature-rich, but some teams find it heavier to onboard and occasionally slower on large projects compared to leaner, commerce-focused setups.
Why Labelbox stands out
- Model-assisted labeling: Built to accelerate labeling using AI helpers, which can improve throughput on large datasets.
- Flexible workflows: Multi-step reviews and rework loops are straightforward to set up and manage.
- End-to-end program features: Covers curation → labeling → QA → export, which helps teams standardize their pipeline.
- Scales across use cases: Common choice when teams are labeling across CV, NLP, and multimodal programs.
Best for
Image-heavy e-commerce initiatives, such as fashion segmentation or visual similarity. Companies with an internal labeling function that want faster tooling and automation.
Not ideal for
Large-scale catalog enrichment where consistency across attributes and categories is the main challenge. -
Encord
Encord is an annotation and data development platform built for teams running large computer vision programs where dataset quality, auditability, and iterative model improvement matter.
It’s a good option if your e-commerce roadmap leans heavily into vision-led features like visual search, similar-product matching, and automated merchandising from images, and you want mature tooling to manage labeling + review across many datasets.
Encord works well for enterprise CV programs, but e-commerce teams that need rapid catalog ops may find it more optimized for CV workflows than for day-to-day taxonomy and attribute normalization.
Why Encord stands out
- CV annotation + QA tooling: Built for image labeling programs with structured review flows.
- Dataset governance: Helpful controls for organizing datasets and managing changes as your schema evolves.
- Scale for enterprise teams: Fits programs with multiple stakeholders, complex workflows, and repeatable QA cycles.
- Model iteration support: Works well when teams continuously refine training data based on model performance and error analysis.
Best for
E-commerce AI teams building vision-heavy capabilities (visual search, similar items, image-based merchandising).
Not ideal for
Catalog ops-first programs where the priority is attribute normalization, taxonomy mapping, and predictable managed throughput across categories.
How to choose an e-commerce data annotation partner (Checklist)
Choosing an e-commerce annotation partner is less about “best tool” and more about fit for your catalog reality—taxonomy complexity, attribute consistency, weekly SKU volume, and QA rigor.
Use this checklist to quickly evaluate vendors on what matters in production: reliable quality, scalable delivery, and smooth handoffs into your search and recommendation pipelines.
Conclusion
E-commerce AI is only as good as the training data behind it. When your catalog has consistent categories, attributes, and visual tags, you get better discoverability & search relevance, thus more conversions.
If your goal is ongoing catalog operations (taxonomy mapping, attribute normalization, listing QA, and steady weekly throughput), pick an e-commerce-first partner that combines process + QA + delivery so quality stays stable as sellers, seasons, and SKUs change.
Taskmonk is often chosen when annotation is not a side project, but a core catalog operation. If your risk is inconsistent attributes across sellers and seasons, and you need a stable weekly throughput. Its combination of a robust platform, domain workflows, QA, and managed delivery is designed for that reality.
Next step: shortlist 2–3 vendors, run a pilot, measure accuracy + throughput + rework rate, then scale the same playbook across the full catalog.
Head: Validate Taskmonk on real SKUs in 24–48 hours



