RLHF platforms collect human feedback at scale to fine-tune LLMs for safety, instruction following, and alignment with human values
The best platforms combine expert annotator workforces, preference ranking tools, and an API infrastructure for SFT and reward modeling
Commercial platforms like Taskmonk, Scale AI, Surge AI offer managed services with vetted annotators across technical domains
Open-source frameworks like Argilla, OpenRLHF, and TRL give teams full control over data collection and training pipelines
Key decision factors include annotator quality, domain expertise, data security, and whether you need managed services or self-hosted infrastructure
Introduction
If you have shipped an LLM to production and watched it confidently hallucinate answers to customer questions, recommend harmful content, or ignore explicit instructions in your system prompts, you know the problem. Pre-trained models learn patterns from massive text corpora, but they do not learn what humans actually want from an AI assistant.
The gap between raw language modeling and useful, safe, aligned model behavior is what RLHF closes. Reinforcement learning from human feedback trains models to generate responses that humans prefer by collecting preference data at scale, training reward models to predict human judgments, and using those reward signals to fine-tune the base model.
This is how ChatGPT learned to follow instructions, how Claude learned to refuse harmful requests, and how every production LLM in 2026 learns to behave like a helpful assistant instead of a next-token prediction engine.
But RLHF at scale requires infrastructure that most teams do not have. You need annotators who can evaluate model outputs across technical domains, platforms that collect pairwise rankings without introducing bias, APIs that integrate feedback loops into training pipelines, and quality control systems that catch low-effort labels before they poison your reward model. The platforms and tools in this guide solve those problems. Some offer managed annotation workforces with domain experts. Others provide self-hosted frameworks for teams that want full control over their data.
This article covers the RLHF platforms built for teams deploying LLMs in production. You will see how commercial services handle workforce operations, what open-source frameworks offer for customization, and where the trade-offs show up when you are choosing between managed platforms and self-hosted tools. If you are fine-tuning models for safety, instruction following, or domain-specific applications, the right RLHF platform determines whether your alignment program scales or stalls.
Let's get into it.
What is RLHF?
Reinforcement learning from human feedback is a technique that fine-tunes pre-trained language models to align with human preferences. The process starts with a base model that has learned language patterns from massive datasets but has not learned what makes a response helpful, harmless, or honest. RLHF teaches the model those distinctions by collecting human judgments at scale and using those judgments to guide training.
RLHF works across domains beyond conversational AI.
In e-commerce, models learn to rank search results based on user preferences.
In content moderation, they learn to flag harmful content while avoiding false positives on nuanced cases.
In code generation, they learn to produce compilable, readable, secure code rather than syntactically correct but brittle implementations.
The common thread is human judgment guiding model behaviour, where pre-training alone falls short.
Now that we understand the role of RLHF, let’s break down how the process works step by step.
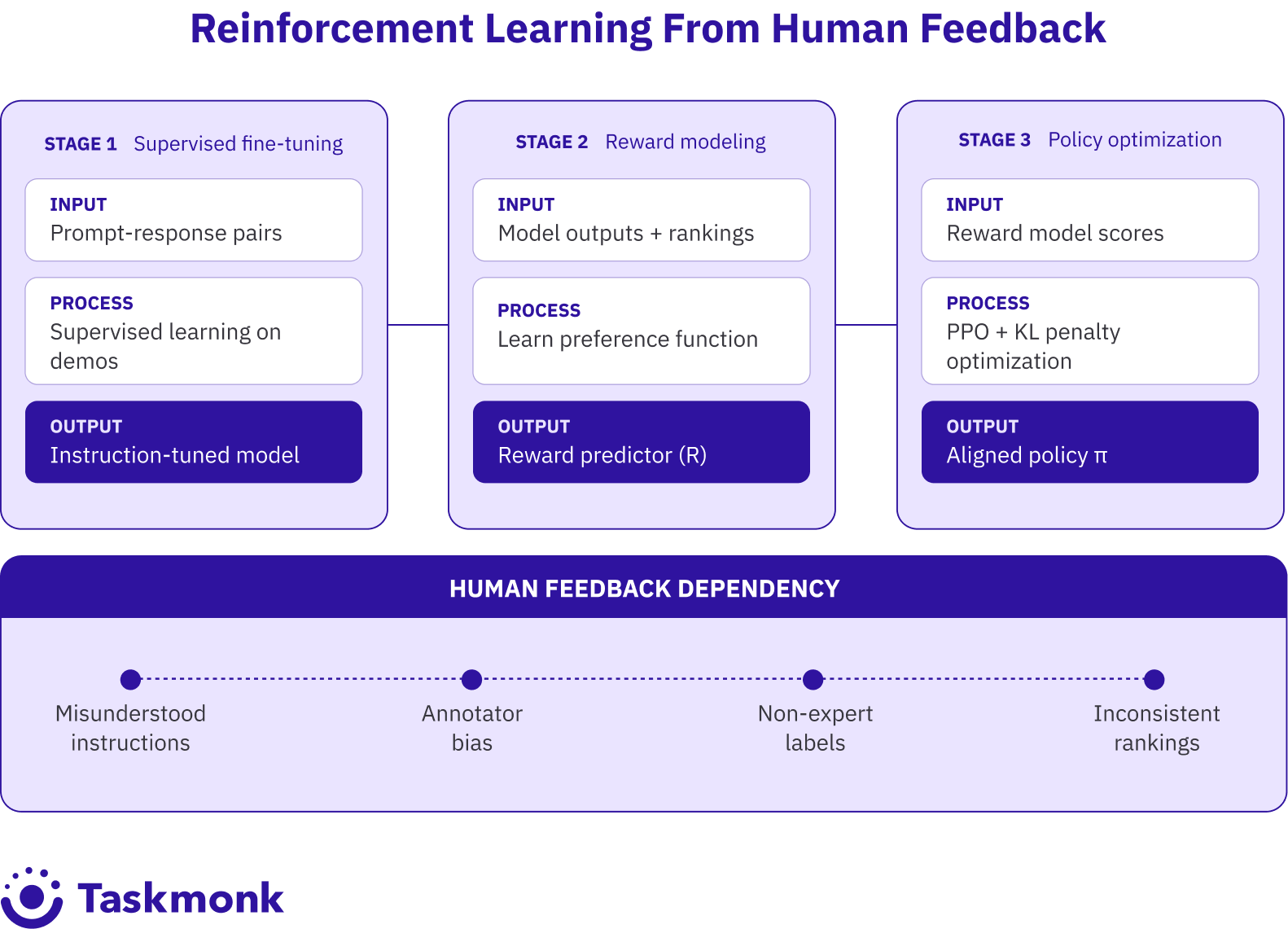
How Does Reinforcement Learning from Human Feedback (RLHF) Work?[AK1]
RLHF runs in three stages:
Supervised fine-tuning (SFT),
Reward modeling, and
Policy optimization through reinforcement learning.
Each stage depends on human feedback collected at scale, and each introduces distinct quality-control challenges.
Supervised fine-tuning
Supervised fine-tuning comes first. You collect demonstration data where human annotators write high-quality responses to prompts. These prompt-response pairs are used to fine-tune the base model in a supervised manner, teaching it to generate responses that resemble the demonstrations. This stage is also called instruction tuning. The model learns to follow instructions by seeing examples of instruction-following behaviour.
Reward modeling
Reward modeling is the second stage. You generate multiple responses to the same prompt using your fine-tuned model, then ask human annotators to rank those responses from best to worst. This creates a dataset of comparisons: for prompt X, response A is better than response B. You train a separate reward model on this comparison data. The reward model learns to predict which responses humans will prefer without needing humans to label every new output.
Policy optimization
Policy optimization is the final stage. You use a reinforcement learning algorithm (typically Proximal Policy Optimization, or PPO) to fine-tune the model so it generates responses that score highly according to the reward model. The RL algorithm adjusts model parameters to maximize reward while adding a penalty term that prevents the model from drifting too far from the supervised fine-tuned version. This keeps outputs coherent and prevents reward hacking.
The bottleneck in all three stages is human feedback quality. If annotators misunderstand instructions, introduce bias, or provide inconsistent rankings, the model also learns those errors.
If you collect feedback from non-experts on technical tasks, the reward model will be wrong about what good looks like. If you run RLHF without structured quality control, you burn the budget on low-quality labels that do not improve the model and sometimes make it worse.
Pro tip: Run inter-annotator agreement checks early in every RLHF program. If three annotators rank the same set of responses and their rankings do not correlate, your instructions are unclear or the task requires domain expertise you have not sourced. Catching this after 10,000 labels costs more than catching it after 100.
The best data annotation tools for generative AI are built to handle these quality control challenges at scale. They provide annotator training, consensus workflows, gold standard test sets, and metrics that surface low-performing annotators before their labels reach your training pipeline.
The RLHF process sounds straightforward in theory, but executing it at scale requires the right combination of tools, workflows, and infrastructure.
Top Tools and Automation Platform for RLHF
The platforms below represent the tools most frequently used by ML teams running RLHF programs at scale. Some are managed services that handle workforce operations end-to-end. Others are self-hosted frameworks that give you full control over data and infrastructure. Each entry covers what the platform does well, where it fits, and what to watch for
1. TaskMonk
TaskMonk is a managed annotation platform for enterprise AI teams needing RLHF workflows, structured quality control, and scalable annotator operations. It supports preference ranking, demonstration data, and multi-stage review pipelines for fine-tuning and reward modeling.
What sets it apart is affinity-based annotator routing with a no-code workflow builder. Tasks are assigned based on domain expertise, medical data goes to clinically trained annotators, and code tasks to engineers, reducing error rates by 15–20%.
TaskMonk offers flexible QC methods: Maker-Checker, Maker-Editor, and Majority Vote, configurable per task type. It also supports model-in-the-loop workflows, enabling direct LLM integration, real-time quality checks, and training-ready exports (JSON, CSV, Hugging Face).
Built for enterprise use, it includes SOC 2 Type II, ISO 27001, and HIPAA-aligned controls, along with SSO, role-based access, and audit trails.
With 480M+ tasks processed, 6M+ annotation hours, and Fortune 500 clients, TaskMonk is chosen for production-grade RLHF with domain experts and audit-ready quality.
Best for: Enterprise AI teams, regulated RLHF programs, high-volume preference data collection with managed workforce, and projects requiring domain-specific annotator routing or consensus QA.
2. Scale AI
Scale AI is the commercial RLHF platform ($750M+ ARR), operating as an end-to-end generative AI data engine. It covers SFT, preference ranking, LLM evaluation, and red teaming through two subsidiaries — Remotasks (computer vision/AV data) and Outlier (LLM annotation). Its managed workforce includes vetted domain experts across law, medicine, STEM, and coding.
Scale is OpenAI's preferred fine-tuning partner and has worked with Meta, Google DeepMind, and national AI safety institutes. It runs adversarial red team testing, operates benchmarks like Humanity's Last Exam, and integrates via API/SDK with standard ML pipelines.
What to watch: A significant customer exodus followed its 2025 Meta partnership over data exclusivity concerns. Pricing is opaque and project-dependent. QC, while solid, is reportedly less rigorous than boutique providers on highly technical tasks. No affinity-based routing or no-code workflow customization.
Best for: Large AI labs, big RLHF budgets, programs needing evaluation and red teaming bundled with annotation.
3. Surge AI
Surge AI is a bootstrapped, profitable managed RLHF platform that crossed $1B ARR in 2025. It operates ~50,000 expert contractors ("Surgers") and is the primary RLHF provider for Anthropic's Claude, with OpenAI and Meta also as clients.
The platform covers preference ranking, demonstration data, and red teaming, with both live chat evaluation (real-time feedback) and async transcript rating (batch ranking). Quality is tracked via gold standard accuracy, inter-annotator agreement, and per-worker trust scores, with low-quality labels auto-reassigned. Integrates via Python SDK and REST API; engineers can spin up tasks quickly without lengthy calibration rounds. SOC 2 compliant.
What to watch: LLM/NLP only, no computer vision, video, or multimodal support. Usage-based pricing gets expensive at high volumes. No no-code workflow builder or affinity-based routing.
Best for: Quality-first RLHF, safety-critical models, expert feedback on technical or domain-specific tasks.
4. Encord
Encord is a multimodal data platform supporting RLHF workflows across text, image, video, and DICOM medical imaging built for teams where LLM fine-tuning is one part of a broader data ops pipeline. Features include comparison ranking, consensus workflows with disagreement resolution, model-in-the-loop integration, and Active Learning to prioritize high-value relabeling and cut costs. Integrates with AWS, GCP, and Azure via API. SOC 2 Type II, HIPAA, and GDPR compliant with SSO, role-based access, and audit trails.
What to watch: No managed workforce, you supply your own annotators. The platform is a data ops tool, not a turnkey RLHF service.
Best for: Multimodal AI teams, integrated data ops + RLHF, and programs spanning LLMs, computer vision, and medical imaging.
5. Labelbox
Labelbox is a training data platform with RLHF support alongside CV and multimodal workflows. Pricing via Labelbox Units (LBUs) makes cost forecasting predictable at scale. Supports preference ranking, demonstration data, consensus review, and escalation routing. Strong on workflow ops task management, review stages, data catalog, and ML pipeline SDKs. Connects to external workforce providers so you avoid direct annotator management. SOC 2 compliant with on-premise deployment for strict data residency needs.
What to watch: Not LLM-native, built for CV and adapted for text. Lacks red teaming, instruction tuning templates, and domain-expert annotator matching. Technical RLHF tasks often need an added expert review layer.
Best for: Unified multimodal pipelines, existing annotation workflows, and programs where RLHF sits alongside broader CV and NLP work.
With the right platform supporting data quality and workflows, RLHF begins to unlock measurable improvements in model behaviour.
Benefits of Reinforcement Learning From Human Feedback (RLHF)
RLHF solves problems that supervised learning alone cannot address. Pre-trained models excel at next-token prediction but fail at alignment: following instructions, refusing harmful requests, and producing outputs humans find helpful. RLHF closes that gap by teaching models what humans prefer through iterative feedback. RLHF do have some benefits, which are as follows:
Instruction following improves dramatically.
Models fine-tuned with RLHF follow multi-step instructions, maintain context across turns, and clarify ambiguous requests instead of hallucinating answers. OpenAI's InstructGPT showed that models aligned with human feedback outperform much larger models on instruction-following benchmarks despite having fewer parameters.
Safety and refusal behaviour become trainable.
RLHF lets you teach models to refuse harmful, biased, or inappropriate requests without making them overly cautious. Anthropic's Constitutional AI approach uses RLHF to train models that decline dangerous tasks while remaining helpful on edge cases. This balance is difficult to achieve with rule-based filtering or supervised fine-tuning alone.
Domain adaptation becomes faster.
Instead of collecting massive supervised datasets for every domain, you collect preference data on a smaller set of outputs. A medical LLM learns clinical reasoning by having doctors rank responses. A legal LLM learns to cite case law correctly by having attorneys provide feedback on generated arguments. The model learns domain-specific quality criteria directly from expert judgment.
User satisfaction increases measurably.
In production deployments, models fine-tuned with RLHF see higher engagement, lower churn, and better user ratings than baseline models. People prefer responses that sound helpful, stay on topic, and avoid condescending or overly verbose language.
RLHF captures those preferences in a way that standard fine-tuning cannot.
So while RLHF improves model behaviour significantly, it’s not without trade-offs. Let’s look at the challenges teams face.
Challenges of Reinforcement Learning (RLHF)
Poor Data Quality & Inconsistent Feedback
RLHF scales poorly without the right infrastructure. The challenges show up in three areas: data quality, annotator bias, and training complexity.
RLHF depends entirely on human feedback. If annotators misunderstand instructions or give inconsistent rankings (often >30% disagreement on ambiguous tasks), those errors directly affect model behaviour.
Solution:
Use gold standard datasets, inter-annotator agreement tracking, and automated QA checks to detect and correct low-quality feedback early.
Annotator Bias
Human feedback introduces biases—confirmation bias, anchoring (favoring first outputs), and salience bias (preferring longer responses). These distort model learning, especially with limited or homogeneous annotator pools.
Solution:
Use diverse annotator pools, clear edge-case guidelines, and structured review workflows (consensus, multi-stage QA) to reduce bias.
High Cost of Scaling
RLHF is expensive. Large datasets (e.g., 50,000+ labels) can cost tens to hundreds of thousands of dollars, with expert annotators increasing costs 3–5x.
Solution:
Use managed annotation platforms and optimized workflows to improve efficiency, reduce cost per label, and scale sustainably.
Training Complexity
RLHF is expensive. Large datasets (e.g., 50,000+ labels) can cost tens to hundreds of thousands of dollars, with expert annotators increasing costs 3–5x.
Solution:
Use platforms with built-in pipelines, model-in-the-loop workflows, and monitoring tools to simplify training and reduce engineering burden.
Reward Hacking
Models may exploit reward signals instead of learning true alignment (e.g., generating longer responses just to score higher).
Solution:
Continuously refine reward models, monitor outputs, and iterate feedback loops to prevent exploitation and improve alignment.
So how do you avoid these pitfalls? It starts with choosing the right RLHF tool. Consider following factors to choose the right one.
Pro tip: Start small with RLHF. Collect 500 to 1,000 preference labels, train a reward model, and evaluate it on held-out examples before scaling to 50,000 labels. If the reward model does not correlate with human judgment on the test set, adding more data will not fix the problem. Fix your annotation instructions, clarify ambiguous cases, and re-train before you scale.
What to consider before choosing the right RLHF tool ?
Choosing the right RLHF platform depends on three constraints: workforce needs, infrastructure capacity, and data security requirements. Map those before evaluating tools.
Workforce Availability
Workforce is the first decision. If you have in-house annotators or access to crowdsourcing, open-source tools like Argilla provide flexibility without vendor lock-in. If not, managed platforms like TaskMonk, Surge, or Scale handle workforce operations end-to-end. For domain-specific tasks (medical, legal, code), expert annotators are essential—general crowdsourcing won’t deliver reliable quality.
Infrastructure & Training Capacity
Open-source frameworks like OpenRLHF and TRLX require GPU clusters, distributed training, and ML expertise, but offer full control. If you lack this setup, platforms that combine data collection with training workflows reduce operational burden and speed up deployment.
Data Security & Compliance
For sensitive data (healthcare, finance, government), ensure the platform supports on-prem deployment, SSO, role-based access, and audit trails. Compliance standards like SOC 2, HIPAA, and GDPR are critical. Open-source tools give full control, but you are responsible for implementing security.
Task Complexity
Simple preference ranking can work with basic crowdsourcing. But nuanced tasks—like evaluating code correctness, medical outputs, or legal reasoning—require domain experts. Platforms that route tasks based on expertise (e.g., affinity-based routing) significantly reduce error rates.
Quality Control Depth
Quality control separates platforms. Look for gold standard datasets, inter-annotator agreement tracking, automated QA checks, and consensus workflows. Real-time quality validation prevents bad labels from entering training data, unlike platforms that only report issues after export.
Integration & Workflow Fit
Check if the platform supports JSON, CSV, Hugging Face datasets, and offers APIs/SDKs for automation. RLHF is iterative—tight integration between data collection, model training, and feedback loops reduces cycle time and friction.
Cost Structure
Cost models vary based on how you build and scale your RLHF pipeline:
Usage-based pricing is flexible and ideal for pilots, but it becomes expensive as volume grows.
Managed services offer predictable pricing and are better suited for large, ongoing programs.
Open-source tools have no license cost, but require investment in infrastructure, engineering, and maintenance.
Why choose Taskmonk?
Most RLHF programs hit the same bottleneck: annotation quality degrades as volume scales, quality control becomes manual after-export work, and rework cycles burn weeks. TaskMonk was built to remove that friction by handling RLHF operations end-to-end with domain-expert annotators, structured workflows, and built-in QC. Here is how see how Taskmonk handles RLHF annotation and LLM data pipelines.
Affinity-based annotator routing:
TaskMonk routes RLHF tasks to annotators based on domain expertise, language fluency, and technical background. If you are collecting preference data for medical LLMs, tasks go to annotators with clinical training. If you are fine-tuning code models, tasks go to software engineers with fluency in the target programming languages. This domain matching reduces error rates by 15 to 20 percent compared to random task assignment and eliminates the need for multiple rounds of annotator retraining.
Three QC methods with real-time quality tracking:
TaskMonk offers Maker-Checker, Maker-Editor, and Majority Vote QC workflows for RLHF. You configure the method per task type. High-ambiguity preference tasks get consensus review with arbitration. High-volume demonstration data gets maker-checker with rejection thresholds. The platform surfaces inter-annotator agreement metrics, flags low-quality labels in real time, and automatically reassigns tasks when quality drops below threshold. Reviewers provide feedback inline, annotators correct in context, and the system tracks quality trends per annotator and per task type.
No-code workflow builder for RLHF:
You configure annotation task UIs, QC stages, and routing rules without writing code. The workflow builder supports conditional logic (route to expert review if confidence score is below threshold), parallel review (send the same batch to three annotators for consensus), and staged QC (rank, review, arbitrate). Changes to workflows take minutes, not sprints. This flexibility matters when you are iterating on reward modeling experiments or testing new alignment techniques.
Model-in-the-loop integration with API support:
TaskMonk integrates directly with your LLM via API. You generate candidate responses, route them to annotators for ranking, and export labeled datasets in formats that plug into training pipelines (JSON, CSV, Hugging Face Datasets). The platform tracks task progress, monitors annotation throughput, and provides real-time dashboards showing completion rates, quality metrics, and annotator performance.
TaskMonk has labeled 480 million tasks, delivered over 6 million annotation hours with a workforce of over 24000 annotators, and supports 10+ Fortune 500 clients across AI, autonomous vehicles, and healthcare programs.
The platform holds a 4.6 out of 5 rating on G2. Teams building production LLMs for enterprise use cases, safety-critical applications, and regulated domains use TaskMonk when they need managed RLHF operations with audit-ready quality control and domain-expert annotators.
Conclusion
The cost of choosing the wrong RLHF platform shows up, in wasted budget, unreliable data, and months of rework. Poor-quality labels, annotator bias, and weak QC workflows quietly derail alignment efforts while teams keep moving forward, assuming the problem is in the model.
The teams that succeed take a different approach. They start with their constraints—not feature lists. They define their workforce needs, level of expertise required, and security requirements upfront. They run real pilots with real data. They test the full workflow—task creation, QA, and export—before committing. And they choose platforms that remove friction at scale, not just tools that look good in demos.
Before you commit to any platform, take these steps:
Run a pilot with your actual use case
Validate quality with real QA workflows, not assumptions
Check how easily the platform integrates with your training pipeline
Evaluate cost and scalability beyond the first batch
The right RLHF platform won’t just help you label data, it will help you move faster, reduce risk, and scale alignment without rebuilding your pipeline later.
If you’re serious about building production-ready LLMs, start by validating your RLHF workflow now, not after problems appear.
Training RLHF models requires more than just a good platform, it needs structured preference data, calibrated raters, and QA workflows that hold up at scale. If you're building or fine-tuning LLMs and AI agents, see how Taskmonk handles RLHF annotation and LLM data pipelines.
Frequently Asked Questions
What is the difference between RLHF and supervised fine-tuning?
Supervised fine-tuning trains models on human-written demonstrations using next-token prediction. The model learns to mimic the style and structure of the examples but does not learn which outputs humans prefer when multiple valid responses exist. RLHF trains a reward model on human preference data (pairwise rankings) and uses reinforcement learning to optimize the model for outputs that score highly according to that reward model. RLHF captures nuanced preferences that supervised learning misses, like tone, safety, and alignment with human values.
How much does RLHF data collection cost?
Costs vary by task complexity, annotator expertise, and volume. Collecting 50,000 preference labels for reward modeling typically costs $30,000 to $150,000 depending on whether you use crowdsourcing ($0.50 to $2 per ranking) or domain experts ($5 to $10 per ranking). Demonstration data for supervised fine-tuning costs more because annotators write full responses rather than ranking existing outputs. A dataset of 10,000 human-written demonstrations can cost $50,000 to $300,000. Managed platforms offer volume discounts and fixed-price contracts for large programs.
Can I use crowdsourcing platforms like Mechanical Turk for RLHF?
Yes, but quality will be inconsistent. Crowdsourcing works for simple preference tasks on general chatbot outputs where no domain expertise is required. For technical tasks (ranking code solutions, evaluating medical diagnoses, judging legal arguments), crowdsourced labels introduce noise and bias. Platforms like TaskMonk, Surge, and Scale vet annotators for expertise and pay premium rates to incentivize quality. If you use crowdsourcing, budget time for extensive quality control, gold standard testing, and annotator filtering.
What is the difference between RLHF and DPO?
Direct Preference Optimization (DPO) is an alternative to RLHF that skips the reward modeling stage. Instead of training a separate reward model and using RL to optimize against it, DPO directly fine-tunes the model on preference data using a modified loss function. DPO is simpler to implement, requires less computation, and avoids RL training instability. However, RLHF with a reward model offers more flexibility for tasks where you need to adjust alignment criteria without retraining the entire model. Both techniques require high-quality preference data collected at scale.
How do I measure if my RLHF program is working?
Track three metrics: reward model accuracy on held-out test sets, model win rate in human evaluations, and production metrics like user engagement and satisfaction. Before scaling, validate that your reward model correlates with human judgment on test examples. If the reward model does not predict human preferences accurately, adding more RL training will not help. After RL fine-tuning, run human evaluations where reviewers compare outputs from your base model, SFT model, and RLHF model. The RLHF model should win significantly more comparisons. In production, monitor churn, session length, and explicit user feedback to confirm that alignment improvements translate to better user experience.
.png)
.png)
.png)
.png)
.png)

.png)