TL;DR
When comparing data labeling companies in 2026, don’t start with “who’s biggest.
Factors that govern the selection of data annotation companies are domain expertise, quality assurance maturity, compliance, and tooling & AI-assistance.
This guide compares five data labeling companies on what enterprise AI teams actually care about: data labeling solutions, annotation quality systems, supported data types, speed at scale, security posture, and workflow fit.
Data labeling companies covered in this blog:
- Taskmonk
- SuperAnnotate
- Labelbox
- Encord
- V7
Introduction
Every AI team looks for a data annotation company that can run a repeatable, secure, and high-throughput data labeling program across multiple modalities (vision, video, audio, text, and 3D) while maintaining high data quality.
Choosing among data tagging companies can sometimes be hard; plenty of platforms look 'advanced.'
If you've ever tried to run a labeling program beyond a pilot, you already know the uncomfortable truth: partnering with the right data labeling service provider isn't a one-time decision - it's like selecting an operating system for your model. The best ai data labeling companies understand this, yet too many teams still treat the choice as an afterthought.
What is Data Labeling and Why Does It Matter?
Data labeling is the process of adding structured information to raw data so an AI model can learn from it. You take inputs like images, videos, audio, text, documents, or 3D point clouds and attach labels that represent what is happening in that data.
Read more on data labeling. Here is a complete guide.
Why does data labeling matter?
Labels are the teaching signal your AI model learns from. If the labels produced by your data labeling services are inconsistent, incomplete, or biased, the model learns those inconsistencies, and you end up debugging "model issues" that are actually data issues.
This is why partnering with gdpr compliant data labeling providers matters - quality and accountability start at the annotation stage.
It affects not just accuracy, but how fast you can iterate, how much you spend on rework, and whether you can trust results across edge cases.
In most data annotation projects, improving label clarity and consistency is the quickest way to lift model performance without changing the model itself.
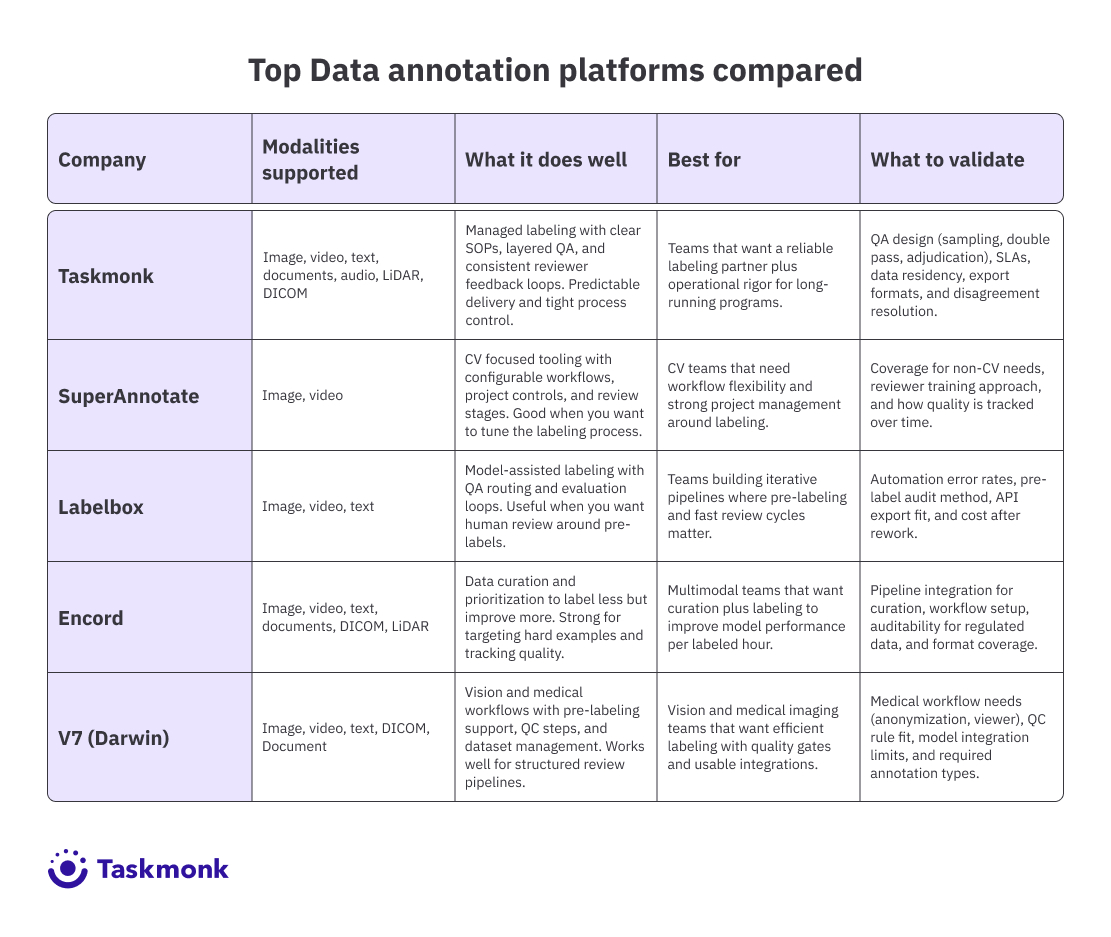
Top Data annotation platforms compared
What to expect from data labeling companies and data annotation services?
A good data labeling company is not just a workforce or a data annotation tool. You should expect a repeatable program that helps you go from raw data to production-ready datasets, with quality controls, security, and predictable delivery.
Here is what to look for:
- Domain-fit workflows: Trained annotators for your domain, clear escalation for edge cases, and fast guideline updates when requirements change.
- Quality assurance maturity: Multi-step review, gold-standard checks, sampling audits, and clear acceptance criteria tied to measurable targets.
- Strong project management: capacity planning, SLAs, predictable throughput, and ownership that keeps delivery moving.
- Tooling and AI assistance: Pre-labeling, model-assisted suggestions, smart QA, and workflow automation that speeds up work without hiding quality issues.
- Security and compliance readiness: access controls, audit logs, encryption, data residency options, and policies for sensitive data handling.
- Integration and export reliability: clean APIs, reproducible exports, versioning, and compatibility with your storage and ML pipelines.
- Transparent pricing: clarity on what is included, review and rework policies, and unit pricing that matches your modality and task complexity.
Here is more on how to select a data annotation platform

Best 5 Data Labeling Companies in 2026
-
Taskmonk
Taskmonk is a global multimodal data labeling company that offers a robust labeling platform, backed by customized industry-specific workflows and managed delivery, enabling teams to run end-to-end data annotation programs across vision, video, audio, text, documents, and 3D datasets.
F500 organizations like Walmart and LG, and e-commerce leaders like Flipkart and Myntra, trust Taskmonk for large-scale labeling programs where consistency and speed both matter.
Verified G2 reviews often highlight faster onboarding, strong customer support, an easy platform UX, and solid workflow features that hold up beyond pilots.
Why Taskmonk stands out
-
Platform features and AI-powered annotation
Taskmonk offers AI-assisted annotation to speed up repetitive work, especially for segmentation and object labeling. It also supports annotator productivity with customizable UI and hotkeys, plus built-in communication and collaboration for faster feedback loops. On the ops side, you can set up QC validation and review workflows, and enrich data batches through APIs using inputs from multiple databases or pre-trained models. -
Strong data quality output through mature QA and domain-ready execution
Taskmonk supports structured QA workflows so quality is enforced consistently across annotators, reviewers, and batches. Teams can set review depth based on task criticality, reducing label drift and rework on edge cases. -
Multimodal data support for annotation
Taskmonk supports multimodal programs across vision, video, audio, text, documents, LiDAR, and DICOM, so teams don't need to use separate tools per modality. This makes governance, reporting, and QA rules easier to standardize across projects. -
Reliable delivery backed by proof at scale
Taskmonk highlights its delivery credibility through scale metrics such as 480M+ tasks labeled and 6M+ labeling hours, as well as $10M+ saved for clients. These proof points signal operational readiness for continuous labeling programs with tight deadlines. -
Enterprise readiness plus data compliance
Taskmonk is suited for enterprise procurement with data hosting flexibility, 99.9% uptime, access controls, and security-first governance. Compliance readiness via SOC 2, ISO 27001, and HITRUST data compliance, which matters for regulated datasets and vendor risk checks. -
Operational scale with managed delivery and workforce depth
Taskmonk combines platform workflows with managed teams, helping maintain predictable throughput during volume spikes. With domain specific data annotator base, which supports rapid ramp-up without rebuilding operations internally.
Common use cases teams run with Taskmonk
- Retail and e-commerce: Product image labeling, catalog enrichment, attributes, and moderation workflows to improve search relevance, recommendations, and ROI.
- Computer vision: Bounding boxes, polygons, keypoints, and segmentation for detection, inspection, and visual QA across real-world datasets.
- Documents AI: Classification and extraction for invoices, KYC, claims, contracts, and support workflows with consistent QA checks.
- Autonomous systems: LiDAR and multi-sensor perception labeling for 3D cuboids, lane and curb annotation, and scene understanding.
- Generative AI: Preference data, instruction datasets, and evaluation sets for tuning and benchmarking model outputs across text, image, audio, and video.
Explore Taskmonk capabilities with a POC -
Platform features and AI-powered annotation
-
SuperAnnotate
SuperAnnotate is an AI data platform focused on building feedback-driven annotation and evaluation pipelines for computer vision teams. It supports custom editors and workflow configuration, which is useful when your labeling needs are not covered by standard “out of the box” tools.
Public G2 reviews report occasional slow performance on large datasets and glitches when switching tasks, so it is worth testing responsiveness on your data and workflows.
Why SuperAnnotate stands out
- Customizable annotation UI and workflows: You can build or tailor labeling interfaces and workflows to match your task requirements, which helps when you have specialized ontologies or unusual data formats.
- Evaluation and traceability support: SuperAnnotate positions evaluation as a first-class workflow, with traceability and analytics to track evaluation steps, reviewer feedback, and iteration performance.
- Enterprise security posture: SuperAnnotate highlights SOC 2 Type II and ISO 27001 alignment via its enterprise messaging and trust materials, which helps when procurement needs documented controls.
- Data hosting flexibility: SuperAnnotate states that data can be stored in US or EU clouds, and it also references options to keep data within your own environment for stricter requirements.
What to validate before choosing SuperAnnotate
If you plan to scale across multiple modalities, confirm modality coverage and workflow consistency. Also, validate how your team will operationalize QA, since platform flexibility is most valuable when you need to mirror an existing labeling process and control workflow steps closely. -
Labelbox
Labelbox positions itself as a comprehensive platform for data labeling and model evaluation, emphasizing acceleration in production through automation and model-assisted workflows. It offers both a platform and access to curated labeling teams, which can help when you need high throughput with specialized expertise.
G2 reviewers flag a steeper learning curve and gaps in customization for certain workflows, so validate setup time, editor flexibility, and your required project controls early.
Why Labelbox stands out
- Model-assisted labeling: Labelbox supports model-assisted labeling workflows, where you set up projects with an ontology and compatible batches, then use assistance to speed up labeling.
- Task-specific models for pre-labeling: Labelbox promotes task-specific models that can pre-label images and videos without code, using foundation models or your own models to reduce manual workload.
- Platform emphasis on evaluation and data workflows: Labelbox highlights core platform capabilities that extend beyond labeling, including evaluation and “AI data factory” style workflows.
- Enterprise security program: Labelbox describes a privacy and security program informed by SOC 2, ISO 27001, and GDPR, which helps align with enterprise controls.
What to validate before choosing Labelbox
For your exact workflow, check how you will measure quality and manage adjudication at scale, especially when model assistance is involved. Also, validate export formats and integration fit with your training and evaluation pipeline. -
Encord
Encord is an AI data platform for multimodal AI that combines annotation with data curation and management. It is often considered by teams seeking a tighter loop between identifying the right data to label, running human-in-the-loop workflows, and improving model performance over time.
Some G2 reviewers mention navigation friction and occasional latency, so you should validate end-to-end responsiveness on your dataset size and review workflow.
Why Encord stands out:
- Annotation and curation workflows: Encord emphasizes data curation and prioritization during labeling, helping reduce labeling volume and focus on high-value samples.
- Broad modality coverage: Encord supports a wide range of modalities, including images, videos, documents and text, audio, DICOM and NIfTI, and LiDAR.
- Active learning orientation: Encord frequently frames labeling in active learning-style loops, which can help teams reduce costs while improving model performance through targeted labeling.
- Security and compliance: Encord states it is SOC 2 and HIPAA compliant, and positions security governance for enterprise AI data projects.
What to validate before choosing Encord
If you are buying Encord for curation, data management, and labeling, validate how those pieces fit into your existing MLOps stack. Also, confirm the QA and review workflow depth you need for your specific domain. -
V7
V7’s Darwin platform streamlines high-quality training data workflows for images, video, and medical formats, including DICOM and NIfTI. It emphasizes seamless model integrations for pre-labeling and rigorous quality checks, providing actionable pairing between human labeling and automation.
Some G2 reviewers call out missing features such as limited export or file handling, so confirm the export formats, workflow controls, and integrations you need before committing.
Why V7 stands out
- Strong support for visual and medical modalities: V7 highlights images, videos, DICOM, NIfTI, and microscopy as key areas of support, aligning with teams working with complex visual datasets.
- Model integration for pre-labeling and quality assurance: V7 enables external or built-in model integration to pre-label data or flag quality issues, facilitating blind comparisons between human labelers and AI models.
- Workflow connection to ML pipelines: V7 positions Darwin as a platform for seamless integration with ML pipelines, streamlining the iteration between labeling and training.
- Enterprise security: V7’s security documentation confirms SOC 2 Type II audit status and GDPR readiness, streamlining vendor risk and compliance validation.
What to validate before choosing V7
If your program is truly multimodal beyond visual and medical imaging, confirm coverage for text and audio workflows. Also, validate how your QA process will be configured for your domain and risk level.
Conclusion
There is no single “best” data labeling company. The right choice depends on your data types, scale, quality thresholds, and regulatory requirements.
One practical way to decide is to shortlist 2 to 3 vendors, validate them on the same dataset, and compare results across measurable criteria: accuracy, disagreement rate, rework rate, turnaround time, and audit readiness. This approach makes quality and delivery gaps visible early, before long-term commitments.
Teams often look for partners that combine managed delivery with platform-level controls to maintain consistency as volumes and modalities grow. Taskmonk is one examplethat teams evaluate in this context.
Head: Connect with Taskmonk for a 24 hr POC.
.jpeg)
FAQs