.png)
TL;DR
In this guide, we compare five top Encord alternatives—Taskmonk, Labelbox, V7, SuperAnnotate, and Dataloop, each containing information on modality coverage, workflow depth, quality controls, automation, integrations, and enterprise readiness.
Tools discussed:
- Taskmonk
- Labelbox
- V7 (Darwin)
- SuperAnnotate
- Dataloop
Introduction
This article is for practitioners comparing annotation tools based on operational fit, not feature checklists.
The market now has several data labeling tools that promise faster labeling, higher quality, and smoother iteration.
Encord is a popular option often shortlisted in that mix. It is used for training data workflows, and its product lineup, including Annotate, Active, and Apollo, is designed to help teams move from raw data to model-ready datasets with collaboration and iteration built in.
But a platform that feels smooth in early evaluations or even projects can reveal rough edges under heavier volume or stricter process needs.
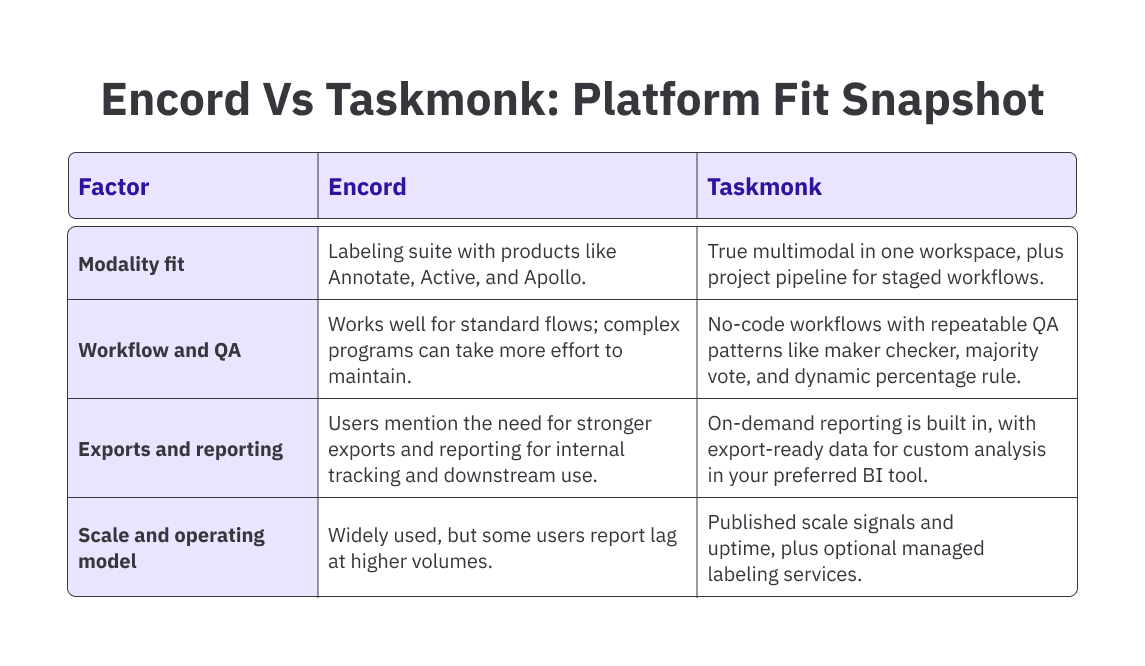
Encord works. But it doesn't work for everyone.
Users hit friction on ontology customization. SDK limitations slow teams down. Costs scale faster than expected. And while the interface is clean, the platform doesn't bend to fit different workflows—you adapt to it instead.
Here are the 6 most common reasons why Encord users switch to competitors :
- Complex workflows take more effort to configure, maintain, and update when specs shift midstream often.
- At higher volumes, teams report lag or latency that slows labeling, review, and throughput.
- Navigation, search, and sorting can feel limited, making it harder to find items across large projects.
- Export and reporting options do not cover every downstream need, adding friction for analytics and handoffs.
- Power-user ergonomics can be a concern: hotkey depth, filters, and project sync are worth re-testing.
- Enterprise expectations like uptime SLAs or custom agreements may require higher-tier support, affecting total cost.
When your AI data pipeline changes, the “right” annotation platform can change with it. That is when teams reassess tools to ensure they still fit current delivery and what is next.
The “best” option depends less on brand and more on fit:
- Your data types and use cases(today + next 12 months)
- The labeling scope and volume of data
- Your Workflow complexity
- Data quality plan and KPIs
- Your scaling model
If you’re looking at Encord alternatives, this guide is for you.
We tested leading data annotation platforms and analyzed recent public reviews to curate a practical shortlist of Encord alternatives for 2026.
You’ll find each tool’s key features, strengths, shortcomings, and how it compares to Encord on workflows, QA, automation, integrations/exports, and governance.
Top 5 Encord Alternatives in 2026
-
Taskmonk
Taskmonk is a unified data annotation platform for enterprise AI teams and scaling startups built to run multimodal labeling in one workspace across text, images, audio, video, LiDAR, and DICOM.
With 480M+ tasks labeled, 6M+ labeling hours, and 24,000+ annotators, Taskmonk has been the platform of choice for 10+ Fortune 500 teams with 99.9% uptime.
Taskmonk also provides managed labeling services for teams requiring end-to-end support from a robust data annotation platform and industry-trained labeling workforce.
Taskmonk’s data annotation tool is rated 4.6/5 on G2. Users consistently highlight flexibility across use cases, ease of onboarding, strong quality-control features, and top notch customer support.
"Exceptional platform backed by outstanding support!" – Geethanjali G., via G2
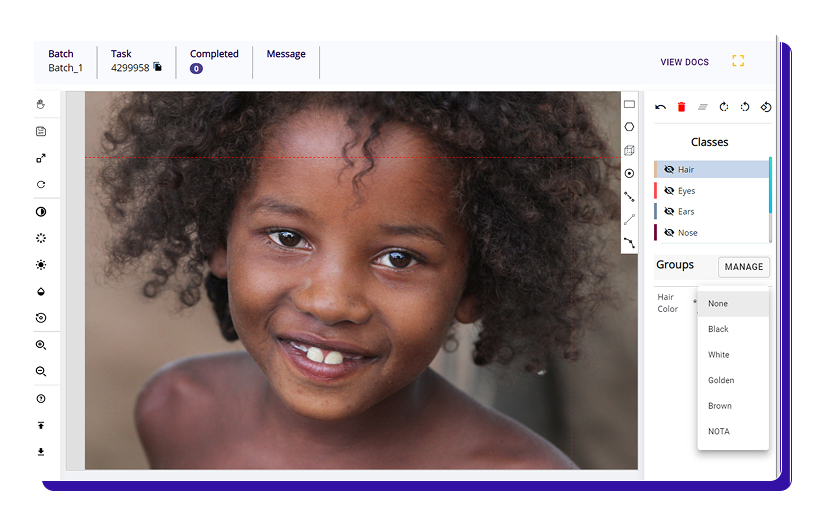
Best for- Teams running multiple modalities and workflows under one operating model, including Computer vision, LLMs & AI agents, search relevance, catalog enrichment, document AI, and more.
- Enterprise programs that need custom workflow orchestration plus execution reliability, not just an annotation UI
- Large backlogs or continuous labeling across multiple projects where predictable throughput and QA discipline matter
Where Taskmonk typically stands out
- True multimodal in one platform: Label across text, images, audio, video, LiDAR, and DICOM in one environment, with consistent workflows and data quality techniques.
- Project pipeline for layered workflows: Useful when one project’s output becomes another project’s input, for example, structuring product text before downstream labeling or review
- No-code workflow and UI building: Configure custom task UIs, role flows, QC steps, and SOP-driven processes without heavy engineering effort
- Rich automation layer: Use AI automations for pre-labeling, standardization, transcription, OCR, and document extraction, and other processors to reduce manual load and tighten consistency
- Quality and governance patterns built in: Supports data quality techniques and QA setups like maker checker, majority vote, golden sets, and codified SOPs for repeatable quality
- Integration and export readiness: Strong APIs and export formats that plug into your training or evaluation stack, with fewer custom scripts to maintain as schemas evolve.
- Operational scale signals: Public scale indicators and uptime posture are helpful if you are planning multi-million item programs or continuous delivery
- Security and governance posture: Designed for enterprise controls like granular access and compliance expectations
-
Labelbox
Labelbox is a training data and model evaluation platform that pairs annotation workflows with model-assisted labeling and GenAI evaluation. It is rated 4.5/5 from 47 reviews, and reviewers often praise it for easy setup and a clean interface.
It is often evaluated for teams that want labeling plus evaluation workflows under one roof.
Best for- Teams building and evaluating GenAI systems that want labeling and structured evaluations in the same platform
- MLOps teams that prefer a mature platform with repeatable project setup and automation options
- Programs that want the option to combine software with external labeling or evaluation support
Where Labelbox typically stands out- AI automation across the lifecycle, including curation, labeling, and QA
- Model-assisted labeling workflows for iterating faster with predictions in the loop
- Evaluation workflows for GenAI, including judge-style evaluation patterns
- Multi-step review and rework patterns for staged approvals
- Managed services option for teams that want platform plus delivery support
Labelbox can also be a practical option if you want a smoother setup experience and a clean interface for getting teams productive quickly.
Before switching, validate two things in a pilot: whether Labelbox matches your exact review and QA flow, and how pricing behaves as volume and review depth increase. -
V7
V7 Darwin is a training data platform primarily used for computer vision & document workflows, with a focus on structured, multi-stage review and automation. On G2, V7 is rated 4.8/5 based on 54 reviews.
Best for- Computer vision teams that want structured multi-stage review workflows with role-based orchestration
- Teams that value automation for routing and validation rules to keep annotation consistent at scale
- Projects where you want strong dataset organization features, including properties for filtering and management
Where V7 typically stands out- Multi-stage workflow design for review and approvals
- Conditional logic and automations for routing work based on rules
- Automated quality checks using validation rules for consistency
- Annotation properties to categorize and manage datasets at scale
- Strong positioning for common computer vision annotation workflows
Before switching, run a pilot to validate your exact annotation types, export formats, and any video or specialized modality needs, so you know it fits your production workflow end to end. -
Superannotate
SuperAnnotate positions itself as an AI data platform for building annotation and evaluation pipelines, with an emphasis on quality management and project operations. On G2, SuperAnnotate is rated 4.9/5, and comparison data highlights good scores for ease of setup and labeler quality.
Best for- Teams that need strong QA discipline and project operations across multiple concurrent projects
- Orgs that want workflow customization and repeatable processes across datasets and teams
- Programs that want tighter integration into storage and ML workflows to reduce handoffs
Where SuperAnnotate typically stands out- Integrated quality management during labeling and review
- Automation for validation and error detection, with feedback loops to annotators
- Workflow and editor customization for different use cases
- Broad modality support positioning across common data types
- Integration focus so annotations move into downstream ML workflows more smoothly
Before switching, validate how it supports your review and rework loop, how it performs at your expected volume, and whether its export formats and integrations match your training pipeline. -
Dataloop
Dataloop is positioned as a broader AI-ready data stack that combines data management, automation pipelines, and a labeling platform. It is often shortlisted by teams that want labeling connected tightly with orchestration and repeatable data operations. On G2, Dataloop is rated 4.4/5
Best for- Teams that want labeling connected to data management and pipeline automation, not as a standalone tool
- Orgs that need structured QA and issue tracking inside the annotation process
- Programs with repeated labeling cycles, where review and QA tasks are part of the workflow
Where Dataloop typically stands out- Pipelines and orchestration as a core concept for repeatable workflows
- Labeling tasks that include annotation, review, and QA stages
- QA and verification workflows with issue tracking and dashboards
- Platform framing that combines tooling and automations to improve dataset quality
- Broader data lifecycle orientation beyond labeling alone
Before switching, pilot for performance at scale, confirm how QA and issue tracking fits your process, and check whether automation and exports plug cleanly into your downstream stack.
How to Make the Choice for the Best Data Annotation Platform
Pick a data annotation tool alternative to Encord based on fit, not feature volume. Decide based on what breaks in real projects: spec changes, reviewer disagreements, and edge cases.
The best data labeling platform is the one that keeps workflows stable and auditable when requirements change.
Validate by running a small pilot with hard samples, measure rework and disagreement, and verify exports into your actual pipeline. If those three hold, the choice is usually correct.
Head: Here is a detailed guide on how to choose a data annotation platform.
CTA: Read the guide
Answer these for yourself to make the right choice
- Do we need to label more than one modality (image, video, text, docs, LiDAR) in the next 6–12 months? If yes, prioritize a unified workflow and shared QA rules over point features.
- How often do our specs change mid-project? If it’s frequent, test versioning, backward-compatible updates, and how fast you can push SOP changes without breaking work in progress.
- Where do disagreements happen today, and can you measure them? Check if the platform supports IAA tracking, clear reviewer escalation, and simple disagreement triage with comments and evidence.
- Can we audit “who changed what, when, and why”? Look for item-level history, reviewer attribution, and repeatable QC rules, not just approval buttons.
- What does “export” really mean for us? Validate that exports match your exact formats (COCO/YOLO/JSONL/DICOM, etc.), preserve metadata, and plug into your training/eval pipeline without manual fixes.
- What’s our failure mode at scale? Test concurrency, latency, assignment logic, and how rework queues behave when you have thousands of items and multiple reviewer roles.
- Can we pilot with hard samples and quantify rework? Run a small dataset of edge cases, measure rework %, time-to-accept, and disagreement rate, then compare vendors on those numbers, not demos.
Conclusion
Data labeling still sits at the center of most real-world AI systems, because even the best models need consistent, well-specified training and evaluation data.
Encord, with its suite of products such as Annotate, Active, and Apollo, aims to support labeling workflows and dataset iteration. It is generally valued for usability, collaboration, and strong annotation tooling.
Teams have to evaluate alternatives when they need deeper customization, new data types to label, smoother performance at scale, or a different fit for their workflows.
Platforms like Taskmonk, V7, SuperAnnotate, Dataloop, and others differ in what they optimize for, including workflow depth, QA controls, automation, enterprise governance, and support across modalities.
Head: Build a robust data labeling pipeline with an industry proven tool.
CTA: connect with our experts for a demo.

.png)
%20(1).png)