TL;DR
AI agents are not like traditional software. They can plan, reason, call tools, and adapt to changing inputs, which means evaluating them requires more than just checking the final answer. AI agent evaluations measure the entire decision process: how the agent understands tasks, chooses actions, uses tools, and produces outputs.
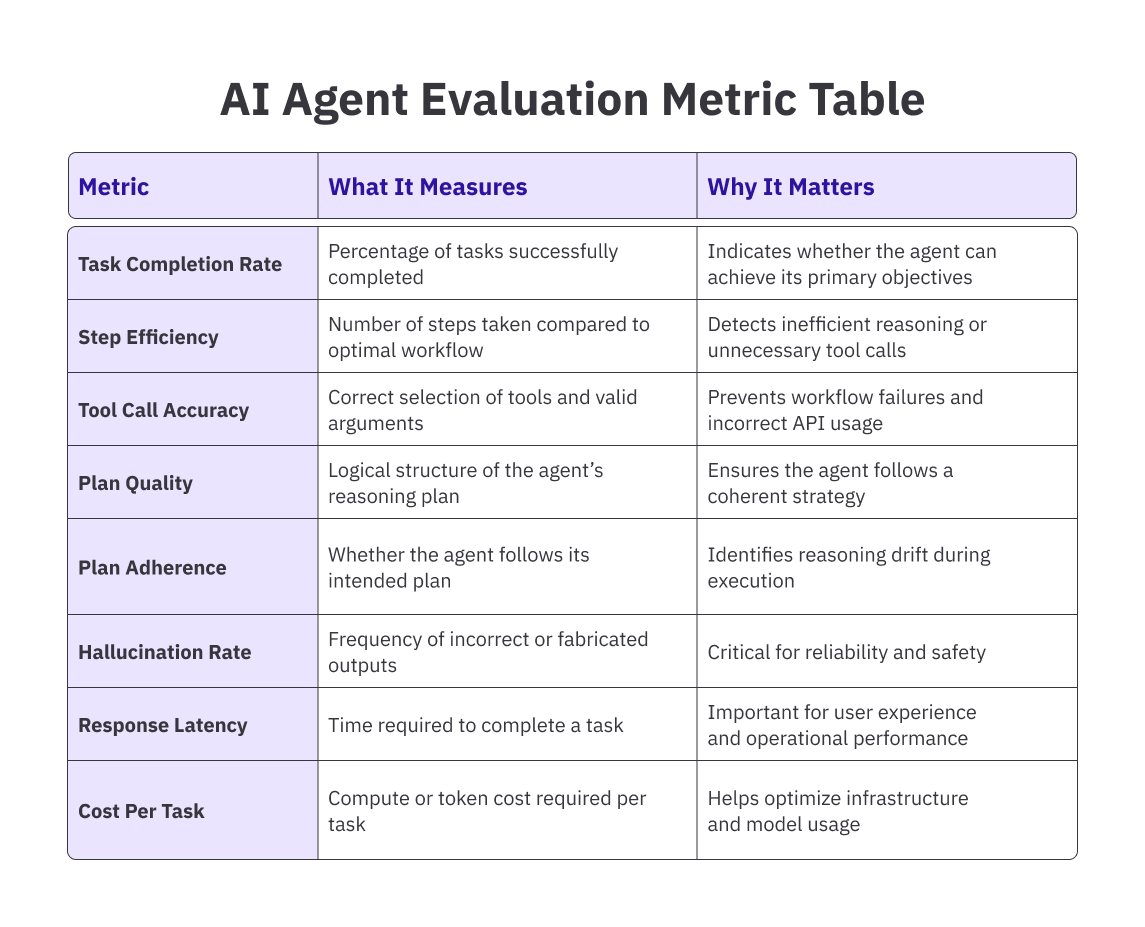
Effective agent evals typically track multiple signals at once. These include task completion rate, tool call accuracy, reasoning quality, step efficiency, latency, and cost per task. Looking at just one metric rarely tells the full story.
A reliable AI agent evaluation framework usually operates across three layers. While component testing verifies individual parts of the pipeline, scenario testing evaluates full workflows, and production monitoring tracks real-world performance through trace-level observability.
Most teams combine automated agent evaluation with human review. Automated metrics catch regressions at scale, while human evaluation helps assess reasoning quality, edge cases, and nuanced user interactions.
The teams that deploy agents successfully are the ones that treat AI agent evaluations as core infrastructure rather than an afterthought. They build datasets from real failures, continuously run evals, and use metrics to improve both agent behaviour and reliability over time.
Introduction
AI agents are capable of planning tasks, retrieving information, calling APIs, and adapting their behaviour based on context. These capabilities make them powerful automation tools, but they also make them significantly harder to test than traditional software.
When an agent performs multiple reasoning steps before producing an answer, evaluating its performance requires more than simply checking the final output. You need to understand how the agent made decisions, whether it used tools correctly, and whether its reasoning process was reliable.
This is where AI agent evaluations come in. Agent evaluations measure how effectively an autonomous system performs across task completion, reasoning quality, tool usage, and safety constraints.
In this guide, we’ll break down what agent evaluation actually means, how it differs from traditional testing, which metrics matter most, and a practical three-tier framework AI teams can use to evaluate agents reliably.
A Brief Overview of Agent Evaluation
Agent evaluation is the systematic process of assessing how well an AI agent performs across all the things it does:
Unlike a chatbot that you can evaluate by looking at its response, an agent operates over multiple steps. It might retrieve data, call an external API, write code, check its own output, and try again if something fails. The evaluation question is not just "was the final answer right?" It is "did the agent take a reasonable path to get there, and would it do the same on a different run?"
AI agent evaluations typically cover four layers:
- Task-level outcomes (did it complete the goal?),
- Step-level behaviour (did it take the right actions in the right order?),
- Tool usage (did it call the right tools with the right arguments?), and
- Safety and alignment (did it stay within its guardrails?). Ignoring any one of these layers gives you a partial picture, and partial pictures are where surprises live.
%20agent%20evaluation.png)
Why AI Agent Evaluation is Different
Traditional software has a property that makes testing relatively tractable: determinism. Given the same input, a function returns the same output. You can write a test, run it a thousand times, and the results are identical. Agents do not work this way.
An agent might solve the same task in three different ways across three different runs, and all three could be valid. Or it might fail in a way that only surfaces on the fourth run because the model drew a different inference from an ambiguous context. Standard unit tests are not built to handle this kind of non-determinism. They check fixed outputs, not reasoning trajectories. And they don't account for the fact that agents compound errors: a wrong decision in step two does not stay contained. It propagates through every step that follows.
There's also the question of what you're evaluating at each layer. Traditional software quality assurance checks whether your code does what the spec says.
Agent evaluation has to go further: it checks whether the agent's understanding of the spec is correct, whether its plan to execute the spec is sound, and whether it can recover when the environment doesn't cooperate. That's a different discipline, and it requires different tools.
One more thing that separates agent evaluation from traditional testing: the failure modes are harder to see. A broken function throws an error. An agent that gives subtly wrong answers, uses more tool calls than necessary, or quietly skips a safety check often looks fine until it doesn't. Good AI agent evaluation frameworks are designed to surface these quiet failures, not just the loud ones.
Pro tip: The most common early mistake in AI agent evaluation is treating it like regression testing for a model. It is not. You are not checking if the output changed — you are checking if the agent's reasoning and behavior are trustworthy across variable conditions. Design your evals accordingly.
How to Evaluate an AI Agent
Evaluation starts with a clear definition of what success looks like for your specific agent. A customer support agent and a coding agent are both agents, but what "working correctly" means for each is completely different.
Before you write a single eval, write out the success criteria. What does the agent need to do? What must it never do? How much deviation from the expected path is acceptable?
Once you have that, evaluation usually runs across three modes: offline testing, simulation, and production monitoring.
- Offline testing runs your agent against a curated dataset of tasks with known expected outcomes.
- Simulation puts the agent in a synthetic environment that mimics production conditions, which is useful for catching failures that only appear in multi-turn or multi-step contexts.
- Production monitoring watches the agent in live use, typically with sampling, anomaly detection, and human review of flagged interactions.
But Running Agent evaluations is only half the problem. The other half is deciding what signals actually indicate good agent behaviour.
That’s where evaluation metrics come in.
Metrics translate agent behaviour into measurable performance indicators, allowing teams to track reliability, efficiency, and correctness over time.
Key Metrics for AI Agent Evaluation
- Task completion rate: What percentage of assigned tasks does the agent complete successfully? But completion alone is a thin signal. An agent that completes tasks by taking 40 steps when 10 would do is not performing well.
- Step efficiency: Measures the ratio of steps the agent actually took to the minimum steps required. Tool call accuracy tracks whether the agent selected the right tools and passed the right arguments.
- Plan quality and plan adherence: Assess the reasoning layer- was the plan logical, and did the agent actually follow it?
Other metrics like hallucination rate (frequency of incorrect outputs), response latency (time required to complete a task), and cost per task (the compute resources required per interaction) round out the picture.
For agents that interact with users, you also need:
User experience metrics: satisfaction scores, escalation rates, and the rate at which users abandon the interaction. These do not replace technical metrics; they sit alongside them.
An agent can have perfect tool correctness and still frustrate users if its responses are unclear. Understanding the full definition of an AI agent makes it clear why a single metric is never the whole story.
The next logical question is how these metrics are actually measured in practice.
Pro tip: Don't evaluate your agent on tasks it was designed to handle well. The useful signal comes from edge cases, ambiguous inputs, and tasks that sit near the boundary of what the agent should and shouldn't do. Build your evaluation dataset from real failures, not from the happy path.
Human vs Automated Evaluation
As expected, both automated and human agent evaluations come with their own pros and cons:
Automated evaluation scales easily. You can run thousands of test cases, track metrics over time, and catch regressions before they reach users. But automated metrics struggle with anything that requires judgment: Was the response appropriate for this user's situation? Was the reasoning actually coherent, or did the agent stumble onto the right answer by accident?
Human evaluation answers those questions, but it doesn't scale the same way. The practical answer is a hybrid: automated metrics for throughput, regression tracking, and cost monitoring; human evaluation for quality calibration, edge case review, and anything where nuance matters. The split between them depends on your volume, your risk tolerance, and what failure looks like in your specific use case.
The Three-Tier Framework for Agent Testing
Most evaluation frameworks converge on a similar structure, even if they use different terminology. Here's a version that works in practice, built around three distinct testing tiers.
How TaskMonk Supports AI Agent Evaluation
Most evaluation pipelines stall not because teams don't know what to measure, but because the underlying data isn't reliable enough to measure against. Ground-truth datasets assembled quickly by generalist reviewers, without versioned rubrics, produce metrics that look real but aren't. TaskMonk is built specifically to fix that layer.
Agent trace labeling: TaskMonk labels agent traces directly via the step-by-step reasoning sequences, tool calls, and decision points that an agent produces during a task. This is not generic text annotation. It is a structured evaluation of agent behaviour at the action level, which is exactly what tier-one and tier-two testing require. If your eval dataset only covers final outputs, you are missing the layer where most agent failures actually originate.
Pairwise and pointwise preference evaluation: For teams running LLM-as-judge pipelines or building RLHF datasets, TaskMonk runs rubric-based preference judgments across helpfulness, accuracy, style, and safety dimensions. Raters are calibrated before scoring begins, and inter-annotator agreement is tracked continuously using Cohen's Kappa and Krippendorff's Alpha. When a scorer drift crosses a threshold, the platform flags it. This means the ground truth your metrics run against is not just labeled, it's verified to be consistent.
Red-teaming at scale. TaskMonk runs structured red-team campaigns that score agents on hallucination rate, PII exposure, toxicity, bias, and jailbreak susceptibility. For teams that operate in regulated industries like healthcare, finance, legal, this is the evaluation layer that satisfies auditors and legal review, not just model performance benchmarks. Red-teaming on a handful of internal cases is not the same as a systematic campaign across thousands of adversarial inputs with calibrated reviewers.
Span-level RAG grounding. For agents that retrieve and cite information, TaskMonk checks grounding at the citation level with each claim linked to a source snippet and unsupported spans flagged for review. This is materially different from response-level accuracy scoring. An agent can produce a response that reads as accurate while drawing on sources that don't actually support what it said. Span-level grounding catches that failure. Response-level scoring doesn't.
Dataset lineage and versioned rubrics. Every label in TaskMonk carries full provenance: guideline version, reviewer ID, timestamp, QC outcome. When you update a prompt, swap a model, or revise your annotation spec, you can trace exactly which labels were produced under which conditions. For teams iterating fast, this is how you avoid the situation where your eval dataset and your current agent spec have quietly diverged without anyone noticing.
Domain-matched annotator routing. Agent evaluation in specialized domains requires reviewers who understand the domain. A generalist annotator scoring a medical agent's reasoning quality and a clinical specialist doing the same review produce fundamentally different signals. TaskMonk routes tasks to annotators matched by domain expertise, language, and demonstrated accuracy on similar work. The 24,000+ strong annotator pool in the Taskmonk ecosystem covers technical, clinical, legal, and multilingual use cases.
It is no wonder, then, that TaskMonk has processed 480M+ tasks across 6M+ labeling hours, supports 10+ Fortune 500 clients, and holds a 4.6 out of 5 rating on G2. See how TaskMonk handles agent evaluation data →
Conclusion
Every evaluation metric your agent produces is only as trustworthy as the data it was measured against. Teams that get agent evaluation right don't just instrument their pipelines well, they treat the ground truth dataset as a product in itself, built with the same rigor as the agent, maintained as both evolve, and owned by someone whose job is to keep it reliable. Teams that get it wrong have dashboards full of numbers that feel meaningful until a production incident makes clear they weren't.
The practical difference between those two teams is usually not model quality or tooling. It's whether the labeled data underneath the eval pipeline was built carefully enough to catch the failures that matter. Trace-level labels, calibrated reviewers, versioned rubrics, domain expertise where the task requires it — these are not nice-to-haves. They are the inputs that make the metrics real.
"Agent evaluation will keep getting harder as agents take on more complex, higher-stakes work. The teams building reliable evaluation infrastructure now are the ones who will be able to move fast later, because they'll know exactly what broke and why.
If you're at the stage of building that infrastructure, TaskMonk's agent evaluation data services are worth a look . You can reach out to the team here.