Compare image classification algorithms like CNN, ResNet, EfficientNet, and ViT. Learn how to choose the right model based on data, compute, and use case.
Picking an image classification algorithm is not just a model decision. It's an annotation strategy decision. CNN is the reliable default for most standard image tasks. ResNet is the go-to transfer learning backbone. EfficientNet gives you high accuracy with less data, as long as your labels are clean. Vision Transformers handle global pattern recognition but need large, consistent datasets. MobileNet is built for edge deployment. SVMs still have a place on very small datasets. This guide walks through each algorithm's strengths, compute requirements, and what each one demands from your labeled data, so you can align your annotation brief to your model choice before training starts, not after.
Introduction
Your team has cleaned the dataset, defined the ontology, and run the first annotation batch. Now comes the question that determines whether all that labeling effort pays off: which image classification algorithm do you train on it?
It sounds like a model architecture question. But for data and ML ops teams, it's really an annotation strategy question. The algorithm you pick shapes how much labeled data you need, what quality bar your labels have to hit, and which edge cases deserve extra annotator attention.
Choosing after the data is already labeled, then discovering the mismatch, is one of the most expensive mistakes in a CV pipeline. This guide covers the major image classification algorithms in use today, what each one demands from your training data, and how to match the algorithm to your actual use case.
Here's how it works.
What is Image Classification in Machine Learning?
When a model looks at a photo and outputs a label 'defective part,' 'cat,' 'malignant tissue' that's image classification. Unlike object detection, which locates and draws boundaries around objects, classification assigns a single label (or a ranked list of labels) to the entire image or to a pre-defined region within it.
In machine learning, this requires two things: a model architecture that can extract meaningful visual features from raw pixels, and labeled training data that teaches the model which features map to which class. The algorithm you choose handles the first part. Your annotation pipeline handles the second. The two are not independent.
There are two main classification paradigms teams work with.
Binary classification assigns one of two labels damaged or not, present or absent.
Multi-class classification assigns one label from a larger set of options, like identifying the species of a plant or the type of road surface in a satellite image.
Multi-label classification, a close cousin, allows multiple labels per image useful when a single image can contain more than one relevant category simultaneously.
The gap between a clean-looking labeled dataset and a model that actually works in production almost always traces back to a mismatch between the algorithm's requirements and what the labels actually provide. That's the decision worth getting right before training starts.
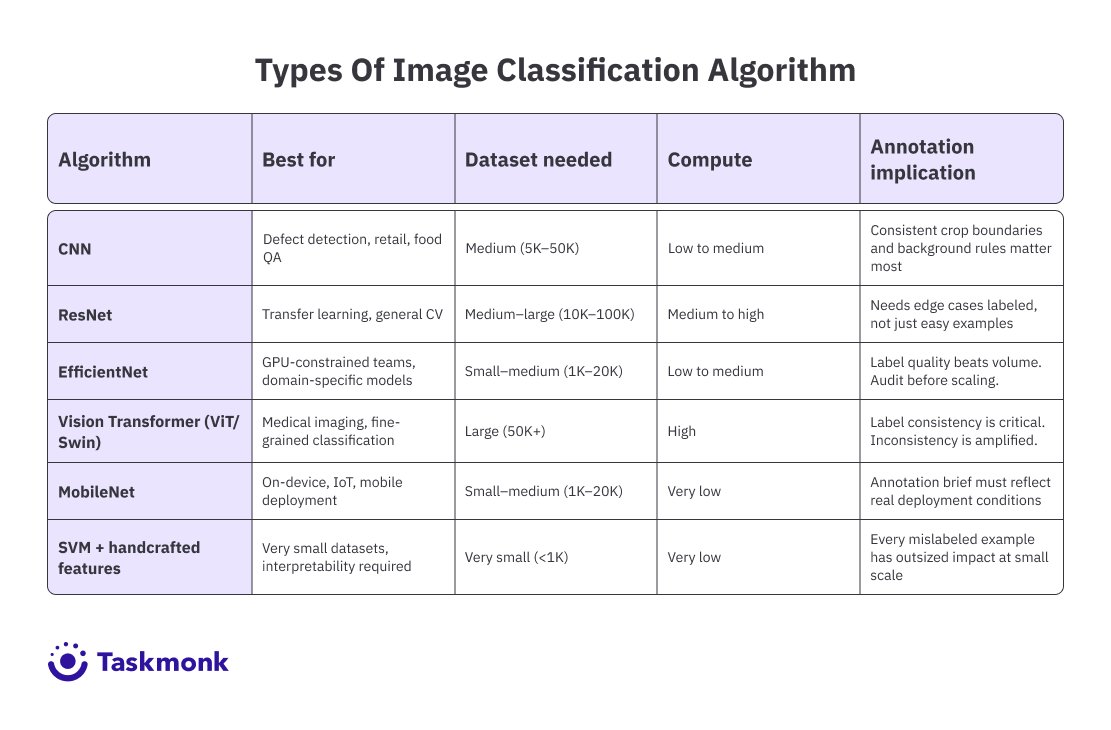
Types of Image Classification Algorithms
Each architecture below is built on a different theory about what makes a vision model learn well. Knowing those differences lets you pick based on your data and deployment realities, not just benchmark leaderboards.
Convolutional Neural Networks (CNNs)
CNNs are the foundation on which most modern image classification in machine learning is built. They use convolutional layers to scan images for patterns, edges, textures, shapes and progressively combine those local patterns into higher-level features. A layer early in the network might learn to detect horizontal lines; a layer deeper in might learn to detect a wheel or a face.
In practice, CNNs work well when you have a moderately sized labeled dataset. They are faster to train than newer models like transformers and perform reliably when your images are similar to the ones used during training. For use cases like defect detection, food quality inspection, or retail product classification, CNNs are usually a strong starting point.
When to choose CNNs:
When you have moderate-sized datasets (10K–100K images)
When your images follow consistent visual patterns (retail, defects, food, etc.
When you need a reliable, proven baseline for production
When not to rely on CNNs alone:
When global context matters more than local features (e.g., complex medical scans)
Pro tip: When using a CNN, your annotation guidelines matter more than you might expect. Since CNNs learn from local pixel patterns, inconsistent crop boundaries or variable background inclusion across annotators will teach the model noise, not signal. Standardize those rules before the first batch.
ResNet (Residual Networks)
Before ResNet, making neural networks deeper didn’t always help. After a certain point, adding more layers actually made the model perform worse instead of better. This happened because the learning signal (called gradients) couldn’t properly reach the earlier layers in very deep networks.
ResNet fixed this problem by introducing skip connections, shortcuts that allow the learning signal to flow directly across layers. This made it possible to train much deeper networks (like 50, 101, or even 152 layers) effectively.
Because of this, ResNet-50 became a widely used and reliable model in real-world applications. Many teams use it as a starting point and fine-tune it on their own data instead of training a model from scratch.
From a data and annotation perspective, ResNet works best when:
You have enough data
Your dataset includes diverse and realistic examples
A common mistake teams make is labeling only the obvious cases and ignoring edge cases. But ResNet learns from whatever data you give it, so if edge cases are missing, the model will perform poorly in real-world scenarios.
In terms of performance, ResNet-50 achieves around 76% accuracy on ImageNet. It’s still a strong and reliable model, though newer architectures can achieve similar or better results with less computational cost.
When to choose ResNet:
When you’re using transfer learning on domain-specific data
When you need a stable, well-tested architecture
When your dataset has good class diversity and edge cases covered
When to be careful:
When your dataset is small and lacks edge-case coverage
When compute cost is a constraint compared to newer models
EfficientNet
EfficientNet came out of a simple but underexplored question: what if you scaled a network's depth, width, and resolution together, rather than one at a time? The compound scaling method introduced balances all three dimensions using a fixed ratio, and the result was an architecture that significantly outperformed prior models on accuracy-per-parameter.
EfficientNet-B0 reaches 77.1% top-1 accuracy on ImageNet with only 5.3 million parameters. EfficientNet-B1 achieves 79.1% accuracy with 0.7 billion FLOPs compared to Inception-v3's 78.8% accuracy at 5.7 billion FLOPs.
For teams with GPU constraints or latency budgets, those numbers are meaningful. EfficientNetV2 extended this further, with faster training and better transfer learning performance on small-to-mid-sized domain-specific datasets.
For annotation teams, EfficientNet's efficiency means it can deliver strong results with less labelled data than ResNet requires, especially when fine-tuning from pretrained weights. That doesn't mean label quality matters less. It means you can reach a useful accuracy threshold with a leaner but well-curated dataset. Quality over volume becomes the operative rule.
When to choose EfficientNet:
When you need high accuracy with limited computing resources
When working with small to mid-sized datasets
When using transfer learning for faster results
When it’s not the best choice:
Production systems where accuracy vs efficiency balance matters most
Pro tip: EfficientNet fine-tuned on a carefully curated domain-specific dataset will consistently outperform a model trained on a larger but noisy dataset. Before expanding your annotation budget, invest in a label audit. Catching systematic annotation errors across 2,000 images will do more for accuracy than adding another 5,000 images labeled the same way.
Vision Transformers (ViT and Swin)
Vision Transformers brought the self-attention mechanism from NLP into computer vision. Instead of scanning an image with convolutional filters, ViT divides the image into fixed patches, encodes each patch as a token, and feeds those tokens through a transformer architecture that learns relationships between every patch and every other patch simultaneously.
The main advantage is the global context. A ViT can model the relationship between a detail in the top-left corner of an image and a pattern in the bottom-right in a single pass, something CNNs approximate only by stacking many layers. For tasks where the diagnostic signal is distributed across the image, certain medical scans, satellite imagery, and fine-grained classification, this matters significantly.
The constraint is data hunger. ViT doesn't have CNNs' spatial inductive biases, so it needs substantially more labeled data to reach comparable performance on small or medium datasets. Swing Transformer addressed some of this with a hierarchical approach, but the general principle holds: if you're working with fewer than 50,000 labeled examples, a modern CNN will typically outperform a transformer on the same data.
Teams using Vision Transformers should plan for larger annotation budgets and stricter label consistency requirements. The model is learning from global relationships, which means inconsistencies that a CNN might ignore can create larger training signal errors.
When to choose Vision Transformers:
When you have large-scale datasets (50K+ images)
When tasks require global context understanding (satellite, medical imaging)
When pushing for state-of-the-art performance
When NOT to choose ViT:
When data is limited
When annotation quality is inconsistent
When compute budget is constrained
MobileNet (Edge and On-Device Classification)
MobileNet was designed specifically for environments where compute is constrained: mobile devices, IoT sensors, embedded systems, edge inference hardware. It uses depthwise separable convolutions to dramatically reduce the number of parameters and floating-point operations required, while maintaining competitive accuracy for its class of use cases.
MobileNetV3 remains the standard choice for teams deploying classification models directly on-device retail shelf scanners, agricultural drones, quality control cameras on manufacturing lines, and diagnostic tools running on modest clinical hardware. The accuracy-to-latency tradeoff is the key metric, not raw accuracy against ImageNet.
For annotation teams building data for MobileNet-based models, the annotation brief needs to reflect real deployment conditions. If the model will run on a camera with variable lighting, you need labeled examples across that lighting range.
If it will classify products at different angles, your dataset needs angular diversity. The model's efficiency won't compensate for training data that doesn't reflect the distribution it will encounter in deployment.
When to choose MobileNet:
When deploying on mobile devices, IoT, or edge hardware
When real-time inference is required
When latency matters more than peak accuracy
When not to use MobileNet:
When maximum accuracy is critical and compute is not a limitation
Traditional Methods: SVM and Handcrafted Feature Approaches
Before deep learning made feature extraction learnable, image classification in machine learning relied on handcrafted features, such as SIFT descriptors, HOG features, and colour histograms, combined with classical classifiers like Support Vector Machines (SVMs). The features were designed by experts who understood what visual patterns mattered for a given task.
SVMs remain in use for specific, narrow scenarios: very small labeled datasets (fewer than a few hundred examples), tasks where interpretability matters and the feature space is well understood, or as a baseline classifier layered on top of features extracted by a pretrained deep network. They are not a general-purpose image classification algorithm for modern CV pipelines.
The annotation implications are different here. Traditional methods rely on the quality of the feature engineering, not on scale. If you're using an SVM on top of pretrained CNN features, the quality bar for your labeled data is high but the quantity required is low. Every mislabeled example has an outsized effect on a small dataset.
When to choose SVM / traditional methods:
When you have very small datasets (<1K images)
When interpretability is important
When used as a baseline or hybrid approach
When to avoid:
Modern large-scale image classification tasks
How to Choose the Right Algorithm for Your Image Classification Use Case
The algorithm choice comes down to four variables:
Dataset size,
Computational constraints,
The nature of the classification task, and
How your training data will be generated.
Getting these four aligned is more important than chasing the highest ImageNet accuracy.
Dataset size is the first filter. If you have fewer than 10,000 labeled images, EfficientNet or MobileNet with transfer learning from pretrained weights will outperform a Vision Transformer trained from scratch.
ViT and Swin shine on large annotated datasets, typically above 100,000 examples, where their global attention mechanism can learn meaningful relationships.
ResNet sits in the middle: powerful with tens of thousands of examples, especially when fine-tuned from ImageNet weights.
Compute and latency constraints come second. For edge deployment, MobileNet is the right answer regardless of what achieves higher accuracy in a server environment. EfficientNet is the go-to for teams that need high accuracy but have GPU constraints. ResNet and ViT are better suited for cloud inference, where latency and memory are less of a bottleneck.
Task complexity determines the architecture family. Local feature recognition (counting objects, identifying product types, detecting defects with visible boundaries) plays to CNN strengths. Global pattern recognition calls for a Vision Transformer: classifying medical images where the diagnostic signal is subtle and distributed, or fine-grained species classification where subtle texture differences across the whole image are what separate classes.
Annotation strategy is the variable most teams skip. EfficientNet's data efficiency means a high-quality, smaller dataset is viable, but only if the labels are accurate and diverse. Vision Transformers punish inconsistency more than CNNs because they model global relationships. MobileNet-based models require annotation briefs that reflect deployment conditions, not idealized studio images. The algorithm choice should inform your annotation brief, not follow from it as an afterthought.
Pro tip: Run a small labeled pilot 500 to 1,000 well-annotated images before committing to a full annotation run. Fine-tune your candidate architecture on that pilot set and check validation accuracy, class-level error distribution, and failure cases. The failures will tell you what your annotation brief is missing before you've labeled 50,000 images the same way.
Tools Used for Image Classification Annotation
The algorithm you choose determines what your labels need to look like. The tool you use to produce those labels determines whether you can maintain that standard at scale. These three platforms represent different approaches to the problem.
Taskmonk
Most annotation platforms optimize for throughput. Taskmonk is built for both throughput and quality control, and that distinction matters when your algorithm choice has specific data requirements.
Image classification annotation in Taskmonk starts with ontology definition: classes, attributes, and per-class rules configured before the first label is produced. Annotators work with a structured task UI that enforces those rules, rather than relying on a separate guidelines document that annotators may interpret differently. For teams fine-tuning EfficientNet on domain-specific data, this consistency at the ontology level directly affects model accuracy.
Pre-labeling with model assistance cuts manual effort on straightforward cases. A model proposes labels; human annotators correct and confirm. For image classification tasks where 70–80% of examples are unambiguous, this dramatically reduces annotation time while keeping humans in the loop for the edge cases your algorithm will encounter in production.
Three QC methods, Maker-Checker, Maker-Editor, and Majority Vote let teams calibrate review intensity to the task. Majority Vote, where multiple annotators independently label the same image and disagreement triggers adjudication, is particularly relevant for Vision Transformer training data, where label inconsistency has a more pronounced effect on model performance than it does with CNNs.
The result is not just faster annotation, but more consistent and reliable training data, something that directly impacts how well your model performs in production. Since different algorithms have different sensitivities to data quality, aligning your annotation workflow with your model choice is critical. Taskmonk’s structured approach ensures that alignment from the start.
Taskmonk has processed over 480 million tasks across more than 10 Fortune 500 clients, and holds a 4.6 out of 5 rating on G2. Reviewers consistently note quick onboarding, high annotator throughput, and quality control workflows that don't create reviewer bottlenecks.
Encord
Encord positions itself as a full-stack data platform: annotation, curation, and model evaluation in one place. Its AI-assisted labeling, built around Segment Anything Model (SAM) integration, reduces manual drawing time on segmentation-heavy tasks. For image classification specifically, Encord's active learning pipelines help teams identify which unlabeled images will most improve model performance useful when you're training a Vision Transformer and need to prioritize annotation budget intelligently.
Encord is typically chosen by enterprise teams working with medical imaging (DICOM and NIfTI), multimodal datasets, or pipelines where annotation needs to connect tightly to model evaluation. The platform's governance features SSO, RBAC, audit logs align with regulated industry requirements. It holds a strong presence in healthcare and autonomous systems annotation.
Labelbox
Labelbox is built around collaboration and cloud-native active learning workflows. Its Model-Assisted Labeling (MAL) feature uses pretrained models to propose labels that human annotators refine, with a clean interface that reduces the learning curve for new annotation teams. The platform integrates tightly with major cloud providers AWS, Azure, GCP making it a natural fit for teams whose ML infrastructure is already cloud-hosted.
Labelbox holds a 4.5 out of 5 on G2, with users noting clean workflow management and solid automation. It's less specialized than Encord for medical imaging but offers broader data type support, covering image, video, text, and geospatial annotation in one platform. Teams running multi-class image classification at scale who need strong collaboration tooling and cloud integration tend to find Labelbox a practical choice.
Industries Using Image Classification AI
Image classification is not a research exercise for most of these industries. It's a production system that makes decisions at volume, and the algorithm and annotation choices feed directly into whether those decisions are reliable.
Healthcare:
Healthcare and medical imaging is one of the highest-stakes deployments. Models classify radiology scans for suspected abnormalities, pathology slides for cell type identification, and dermatology images for lesion risk stratification. Vision Transformers are increasingly used here because the diagnostic signal is often distributed across the whole image, not concentrated in a local region. Annotation for these use cases requires domain-expert annotators and strict inter-annotator agreement protocols.
Retail and e-commerce
Retail and e-commerce teams use image classification to power product search, catalogue categorisation, visual recommendation systems, and product imagery quality assurance. EfficientNet and ResNet are common here, often fine-tuned on domain-specific catalogs. The annotation challenge is to scale millions of product images combined with a need for consistent class boundaries across categories that may overlap.
Manufacturing
Manufacturing and industrial quality control require classifying components as defective or conforming in real time on production lines. MobileNet-based architectures dominate because inference often happens on-device, close to the camera. Annotation for this use case must mirror real production conditions: variable lighting, different angles, partial occlusion. A classifier trained on idealized images will fail when deployed on the line.
Agriculture and environmental monitoring
Agriculture and environmental monitoring use image classification across satellite imagery, drone footage, and ground-level photography. Crop disease classification, weed identification, land cover analysis, and livestock health monitoring all rely on models trained on annotated images collected in field conditions. The annotation challenge is domain shift: models trained on one region or season often generalise poorly to data from different conditions.
Autonomous vehicles and robotics
Autonomous vehicles and robotics use classification as one layer in a broader perception stack, identifying road signs, traffic signals, surface types, and obstacle categories. Data diversity and annotation coverage of rare but critical classes (unusual road conditions, atypical signage) is where most of the production risk lives.
Conclusion
The teams that get image classification right in production share one habit: they treat the algorithm choice and the annotation strategy as the same decision. They don't label a dataset and then pick a model. They decide what the model needs, in terms of data volume, label consistency, class coverage, and edge case representation, and then build the annotation pipeline to deliver that.
The algorithm landscape in 2026 gives you options that were genuinely difficult to access a few years ago: EfficientNet delivers high accuracy on lean, well-curated datasets; Vision Transformers handle global pattern recognition in ways CNNs can't match; MobileNet makes on-device classification tractable. But none of those architectural advantages survive a labeled dataset that doesn't meet the model's actual requirements.
The practical truth is this: your annotation brief is as important as your model selection. Write it after you've decided which algorithm you're training. The algorithm tells you what the labels need to be.
FAQs
What is the best algorithm for image classification?
It depends on your dataset size, deployment environment, and the nature of the classification task. EfficientNet is the best general-purpose choice for teams with moderate labeled datasets and compute constraints. Vision Transformers outperform CNNs on large-scale datasets with global pattern recognition tasks, like medical imaging. MobileNet is the right answer for edge deployment. ResNet remains a reliable baseline with pretrained weights available for most frameworks. If you're unsure, start with EfficientNet-B0 fine-tuned on your data and benchmark from there.
What are the main types of image classification in machine learning?
Retail and e-commerce teams use image classification to power product search, catalogue categorisation, visual recommendation systems, and product imagery quality assurance. EfficientNet and ResNet are common here, often fine-tuned on domain-specific catalogs. The annotation challenge is to scale millions of product images combined with a need for consistent class boundaries across categories that may overlap.
How much labeled data do I need to train an image classification algorithm?
For fine-tuning a pretrained model like EfficientNet or ResNet on a new domain, 1,000 to 10,000 labeled examples per class is usually a reasonable starting range assuming the labels are clean and diverse. Vision Transformers typically need more, often 10,000 or above per class, because they lack the spatial inductive biases that CNNs use to generalize from less data. Training from scratch without pretrained weights requires substantially more. A labeled pilot of 500 to 1,000 examples is a good first check before committing to a full annotation run.
What image classification techniques work best for small datasets?
Transfer learning is the most reliable technique for small datasets. Fine-tuning EfficientNet or MobileNet from ImageNet-pretrained weights lets you adapt a model that already understands visual features without needing the dataset scale to learn them from scratch. Data augmentation flips, rotations, colour jitter, and cropping expand your effective dataset size during training. Few-shot learning approaches exist but require careful evaluation; they often underperform fine-tuned CNNs unless the few-shot setup is well-matched to the task. For most small-dataset classification problems, a carefully curated 1,000-example annotated dataset with EfficientNet fine-tuning is more practical than a complex few-shot approach. See how image annotation quality affects small-dataset model performance.
How does image classification differ from object detection?
Image classification assigns a label to an entire image or a pre-defined image region. Object detection localizes objects within an image by predicting bounding boxes and assigning a class label to each box. Classification is simpler computationally and requires less annotation effort, one label per image rather than one box with a class per object. Detection is the right task when you need to know where something is in addition to what it is. Many production pipelines use both: a fast classifier to screen images, followed by a detection model only on images the classifier flags as containing something of interest.
Lorem Ipsum is simply dummy text of the printing and typesetting industry.


.png)
%20(1).png)
.png)

