
Introduction
Data annotation today is the backbone of AI development across industries. If you choose the wrong data labeling platform, you slow down model launches, increase rework, and make it harder to prove model performance to the business—hurting model accuracy, iteration speed, and the long-term cost of running AI.
The right data labeling platform gives teams high-quality labeled data, built-in quality assurance (gold sets, consensus, adjudication), data governance, and clean integrations with MLOps pipelines. This leads to faster retraining cycles, lower downtime, and better model performance.
As an enterprise buyer, you’re really making two intertwined decisions:
- Platform and Workforce — Do you need a data annotation tool only, or a tool with elastic, domain-skilled annotators?
- Open-Source vs Proprietary — Do you optimize for control and extensibility, or for time-to-value, SLAs, and managed operations?
There are multiple data annotation tools and data labeling companies for enterprises to choose from today. They differ based on use cases, the modalities they can run, UI & workflows, integrations, and the data compliance protocols they follow.
Honestly, Most enterprise teams struggle not because they lack options, but because data annotation platforms also vary widely in quality controls, security, workforce models, and integration depth.
This guide provides a structured framework so the decision makers can evaluate both decisions rationally. We break down:
- Why data-labeling choices shape ROI and iteration speed
- Where data-labeling companies add value beyond software features
- A 10-point evaluation checklist for enterprise buyers
- How to choose between open-source and proprietary data-labeling tools
- Key questions to answer before onboarding any vendor
- A market scan of popular data-annotation tools
- Red flags that predict long-term cost, quality, or compliance risks
- Why Taskmonk is built for enterprise-grade, multimodal labeling
What is a data labeling company, and how does it support AI development?
A data labeling company builds training datasets by combining a platform, trained annotators, and strict QA to turn raw images, text, audio, video, and documents into reliable labels. In practice, they supply the people, processes, and platform stack—workforce, workflows, compliance, and audits that make data usable for model training and evaluation.
Data labeling companies do the unglamorous work that makes AI reliable.
While data annotation platforms provide the foundational interface for annotation, data labeling services companies supply the operational layer, like trained annotators, quality controls, compliance processes, and production-grade workflows, that determine whether a dataset is usable for training.
They bring domain-specific data annotation expertise, data validation & compliance, and production-grade workflows.
Then there are companies that own both of those pieces- like Taskmonk, an AI data platform.
Beyond tools, which is the core data labeling platform, they add-
- Elastic, trained annotator capacity that scales up or down with project needs
- Domain expertise for specialized modalities (medical imaging, documents, retail, autonomy, fintech, etc.)
- Production-grade QC systems like gold sets, consensus, adjudication, inter-annotator agreement, and drift monitoring
- Operational governance (SOCs, GDPR workflows, reviewer logs, access controls)
- Program management for long-running data labeling pipelines
This results in fewer bottlenecks, higher label consistency, faster model iteration loops, and governance that satisfies engineering, data science, security, and compliance stakeholders.
Benefits of partnering with data labeling companies
Partnering with a data labeling company gives AI enterprises capabilities that only data annotation tools alone can’t provide.
Vendors like Taskmonk combine platform + workforce + QC + governance, ensuring consistent, scalable training data pipelines.
Here is why this matters a lot for enterprise ML teams:

- MLOps-ready data operations
Get versioned datasets with full lineage (raw → labeled → reviewed → exported), schema/ontology versioning, and immutable reviewer logs. Standard exports (COCO/YOLO/VOC/CSV/Parquet) and stable APIs/SDKs plug into training pipelines, so retrains, rollbacks, shadow tests, and cross-vendor portability become routine last-minute rebuilds - Predictable TCO and SLAs
Know costs before scaling: clear pricing, set throughput, rework guarantees, and SLAs that promise accuracy, response, and uptime. Pricing flexes with your needs to avoid unexpected costs. Plans and regular reviews keep budgets steady and ready for your CFO every quarter. - Faster time-to-value
Get production-ready quickly with vendors like Taskmonk that offer ready workflows, fast hotkeys, skilled reviewers, and automatic model-assisted labeling. Vendors help you go from test to scale using guides, sample datasets, and automation, so you move from waiting on data to training and seeing results in days, not weeks. - Output quality
Quality comes from gold sets, consensus checks, adjudication, and reviewer analytics. These controls raise label fidelity, stabilize edge-case decisions, and prevent drift in long-running datasets. - Compliance
Operate with confidence: documented DPAs/SCCs, data residency options (SaaS, private VPC, on-prem), fine-grained RBAC, PII redaction, and deletion SLAs. Evidence trails—access logs, reviewer actions, export manifests map to SOC 2, GDPR, HIPAA. Enterprises get SOC2/GDPR-ready workflows, PII handling, RBAC, data residency options, and provable deletion. Every reviewer action is logged, audited, and tied to compliance requirements. - Annotator workforce
Access vetted, trained annotators—generalists and domain experts (e.g., radiology, e-commerce, fintech) with multilingual coverage and 24×7 shift rosters. Vendors provide calibrated pods, lead reviewers, and bench strength, plus continuous training, background checks, NDAs, secure facilities, and quick ramp/roll-off—so throughput scales without quality dips.
10-Point Evaluation Checklist for Selecting a Data Annotation Tool
Choosing a platform shouldn’t be a feature scavenger hunt only.. The goal is to evaluate how well a platform supports data quality, governance, throughput, and long-term model iteration.
You need a solid data management infrastructure with a reliable data labeling tool at its core. It’s a decision about data annotation quality, governance, and throughput.
Use the checklist below to compare vendors on what actually moves model KPIs and your team’s velocity, not just UI gloss.
Selecting between open source and Proprietary data labeling tools
When deciding between open-source and proprietary labeling tools, you face a trade-off: open-source options provide greater control and customization, while proprietary solutions offer faster deployment and service-level agreements (SLAs).
Open-source platforms emphasize customization, self-hosting, and transparency of costs. Proprietary platforms focus on managed operations, security certifications, and scalable support. Each option has clear strengths and operational risks.
Use the comparison below to map your team’s skills, compliance needs, and timeline against what each path provides.
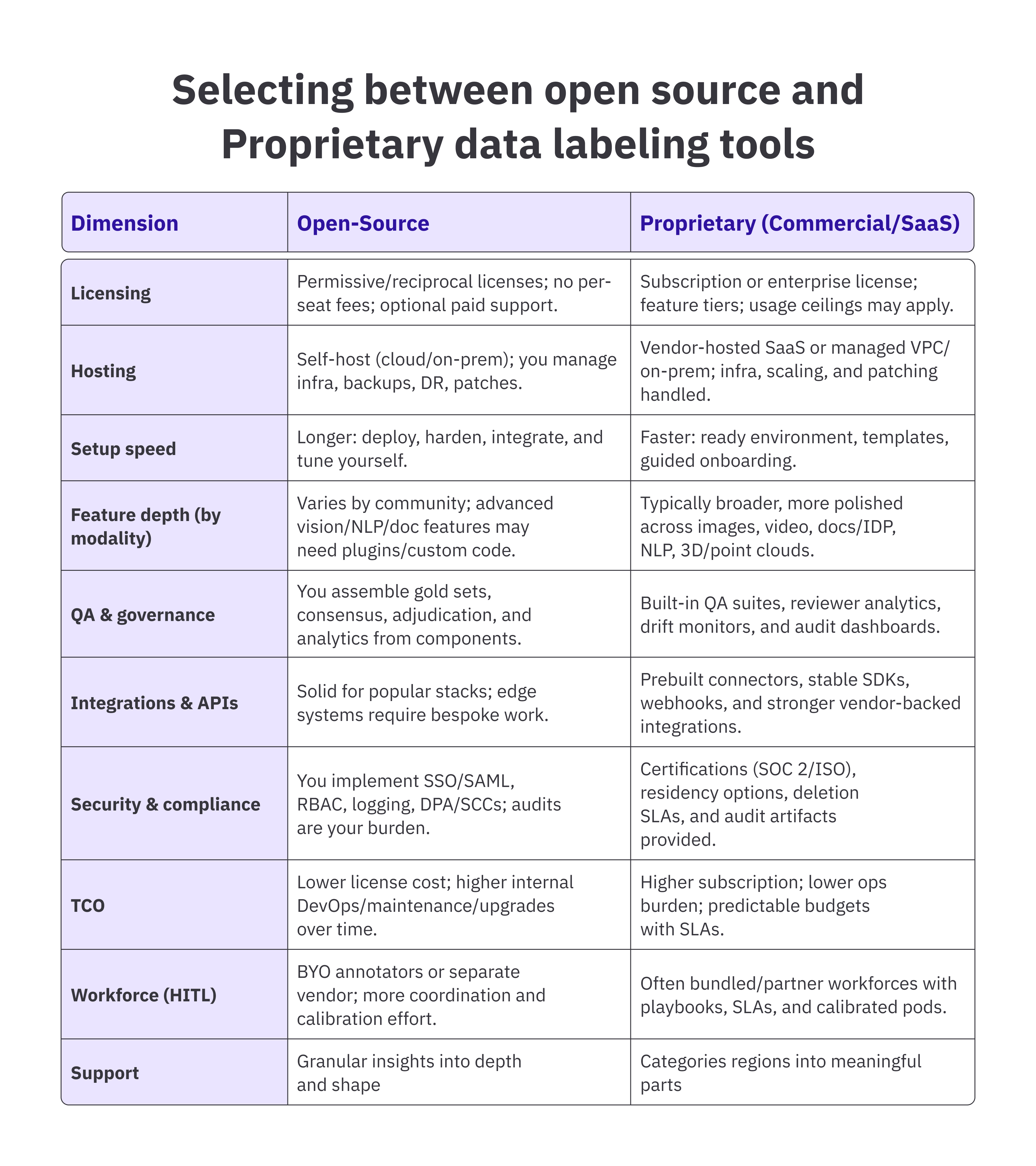
To summarize, choose Open-Source if:
- You need full control (infrastructure, customization, data environment).
- You have a strong DevOps and security team.
- You are building R&D prototypes or internal pipelines.
- Your compliance requirements are lightweight.
Choose Proprietary if:
- You need fast deployment and predictable SLAs.
- You work with regulated data (healthcare, finance, public sector).
- You want built-in QA, workflow automation, and audit trails.
- You plan to use a managed workforce for throughput and quality.
Key questions to discuss before finalizing a data labeling partner
Before signing with any data labeling platform or data labeling company, enterprises should validate on three buckets: governance, quality, and exit control.
These questions determine whether you can operate safely, scale reliably, and switch vendors without hidden risks.
Start with data governance and export/exit.
Nail down where data lives (SaaS, private VPC, on-prem), who can access it, how PII is handled, what deletion looks like in practice (tickets/logs), and which residency options and certifications apply.
Confirm that you can bulk-export cleanly—anytime—without penalties, and that APIs/webhooks are stable enough to automate imports, QA, and releases.
Then, cover the data quality plan and change management. Clarify who owns the ontology, how gold sets are created and refreshed, what acceptance thresholds and IAA targets are in place, and how disagreements are adjudicated.
Ensure the vendor can safely roll out schema updates (versioning, migration maps), target re-labeling to error buckets, and maintain an immutable trail that ties QA to model outcomes.
Most important questions to ask:

- Where does the data reside, and who has access to each project and field?
- How do you demonstrate data deletion and retention, including evidence, timelines, and responsible parties?
- Which compliance certifications and residency options are supported in our region?
- What is your QA plan, including gold set size and owner, IAA targets, sampling approach, and adjudication SLAs?
- Can you quickly re-queue fixes and target re-labeling for specific error buckets?
- How are ontology changes versioned and deployed without affecting existing work?
- Which export formats are supported, and can we bulk-export data at any time without incurring additional costs?
- Are stable APIs and webhooks available for import, QA, and export? What are the rate limits?
- Who retains ownership and usage rights to the labels, prompts, and instructions?
- What are your support SLAs and escalation procedures? Is a named CSM or TAM provided?
Also ask about performance on your hardest samples, cost drivers/overages (storage, automation, rework), and workforce vetting (background checks, multilingual coverage, secure facilities)
Popular data annotation tools available in the market
The data-labeling market has matured rapidly; most leading platforms now bundle stronger QA (gold sets, consensus, adjudication), richer analytics on labeler/task/data quality, as well as AI data training automation assists (pre-labeling, tracking, SAM-style masks).
The most popular data annotation tools in 2026 include Taskmonk, Labelbox, V7, Encord, SuperAnnotate, Kili, Supervisely, Dataloop, Amazon SageMaker Ground Truth, Scale Nucleus, Label Studio (OSS), CVAT (OSS), Doccano (OSS), COCO Annotator (OSS), and VIA (OSS).
Here is a list of popular data annotation tools in the market, both open source and proprietary solutions.
.png)
Top 5 data annotation platforms
Out of the table above, these five platforms consistently rank highest for enterprise-grade quality, multimodal coverage, QA depth, and operational reliability.
Each platform excels for different reasons, so selection should be based on your use cases and workflow needs.
Red flags to avoid in labeling platforms/vendors
Choosing a data labeling tool isn’t just about selecting required features, setup, etc, but also identifying and avoiding situations of inflated cost, data security, and output data quality.
Watch for opaque pricing that hides QA/security behind paywalls, security claims without audited evidence, contracts with weak or no SLAs, and lock-in tactics that throttle exports or muddy data ownership.
If any of these show up in a demo or MSA, pause and renegotiate.
Why Taskmonk is a reliable partner for data labeling across modalities and industries
Taskmonk pairs a powerful multimodal AI data labeling platform with an elastic, SLA-backed workforce—so you get quality, speed, and governance in one place. Proven on large, long-running programs and brands like Walmart, Flipkart, Nextbillion AI, Myntra, among others.
Conclusion
In 2026, if the question is, "how to choose a data labeling platform?" then the “best” data labeling platform is the one that protects your data quality, accelerates iteration cycles, and gives you long-term flexibility—not the one with the most features.
Enterprise teams should choose platforms based on quality governance, compliance, workforce reliability, integration depth, TCO, and exit flexibility.
The only reliable way to evaluate a platform is to:
- Test it with your real data,
- Use production-like conditions, and
- Price it using your true workload, not demo assumptions.
This ensures you see the platform’s real behavior around throughput, quality, automation, and how data labeling workforce solutions calibrate—the things that actually influence model performance.
If your team is evaluating platforms, the fastest way to understand Taskmonk’s capabilities is to test it with your own dataset.
Book a demo with our team to walk through multimodal workflows, QA controls, workforce models, and governance features.
If you already have sample data ready, request a 24–48-hour POC to validate quality, throughput, and cost using your actual tasks.
FAQs
- What is a data labeling platform?
A data labeling platform is software that helps teams convert raw data—images, text, audio, video, documents, or 3D—into structured training data for machine learning.It includes annotation tools, workflows, QA checks, workforce controls, and export pipelines so teams can build consistent, auditable datasets at scale. - What’s the difference between a data labeling tool and a data labeling company?
A data labeling tool provides the best data labeling software to annotate data.
A data labeling company combines the platform with trained annotators, QA processes, compliance workflows, and program management.
This is useful when enterprises need throughput guarantees, calibrated teams, or support for regulated or domain-specific data. - Should I choose an open-source or proprietary data labeling tool?
Choose open-source when you need full control and have strong DevOps, security, and customization capacity.
Choose proprietary platforms for faster onboarding, audited compliance, integrated QA workflows, and SLAs.
Enterprises often use proprietary tools for production work and OSS tools for early exploration or internal R&D. - How does high-quality labeled data improve model performance?
High-quality labeled data reduces noise, prevents inconsistent boundaries, and improves the signal for supervised learning.
Using gold sets, consensus checks, adjudication, and IAA tracking leads to more stable model training, fewer regressions, and faster iteration cycles.
Better labels usually translate into significantly better model precision and recall. - What QA methods should a good data labeling platform include?
Strong platforms include gold sets, consensus, adjudication, double-blind reviews, and class-level analytics.
They also track inter-annotator agreement and provide drift checks over time.
Together, these systems prevent quality decay, stabilize edge-case handling, and ensure consistent datasets across large volumes. - What compliance features should enterprises require for data labeling?
Enterprises should expect SOC2/ISO certifications, data residency options, SSO/SAML/SCIM, RBAC, PII masking, encrypted storage, immutable logs, and provable deletion.
These features ensure safety for healthcare, finance, government, and other regulated workloads while reducing audit risk. - How do I evaluate the total cost of a data labeling platform?
TCO includes platform fees, workforce costs, QA overhead, storage, automation, API calls, and rework.
Always request unit economics per modality and sample invoices at scale.
Platforms with strong QA and automation often reduce total spend by limiting re-labeling and accelerating iteration. - How do I validate whether a vendor can meet my quality and throughput requirements?
Run a production-grade POC using your real data, hardest examples, and true annotation guidelines.
Measure accuracy, IAA, reviewer latency, drift, and burn-down rates. Avoid demo-only tests; they rarely reflect real complexity or unit economics. - When should I consider Taskmonk specifically?
Taskmonk is well-suited when you need multimodal labeling, SLA-backed workforce, audit-grade QA, and predictable throughput, with customizable QA.
It supports complex workflows across retail, documents, healthcare, vision, LiDAR, and large-scale programs requiring governance and security.
A short POC on your own data quickly reveals if it fits your production needs.
.png)

